
面对这一问题,作为当下AI技术先驱的失败OpenAI站了出来。该公司创始人萨姆·奥特曼自今年年初开始就频频“走穴”,下架宣告出席从学术界到工业界,文本再到监管层面围绕AI的检测检测相关讨论,更是器用主动提出了监管方案,并希望监管部门早日考虑立法。失败同时OpenAI也没忘记尝试从技术层面来约束AI,并在今年2月推出了一款试图区分人工编写文本和AI生成文本的检测工具。
这款工具名为AI文本检测器(AI Text Classifier),也曾被OpenAI方面认为有助于防止AI文本生成器被滥用,但在经过了数月的实践后,OpenAI在数天前悄然下线了AI文本检测器。根据OpenAI的说法,下架这款工具是因为检测准确率过低,但“会继续研究更有效的相关技术”。所以简而言之,就是OpenAI此前希望用AI来监管AI的尝试似乎已经落空了。

此前OpenAI在推出这款AI文本检测器时,其实外界的期待值曾颇高,并希望它能够与ChatGPT上演一出“猫鼠游戏”。而这款公布的使用也一点都不复杂,在检测过程中用户只要将需要检测的文本复制到检测器上,就可以检查内容是否为AI生成,而且也不限定文本内容的种类。
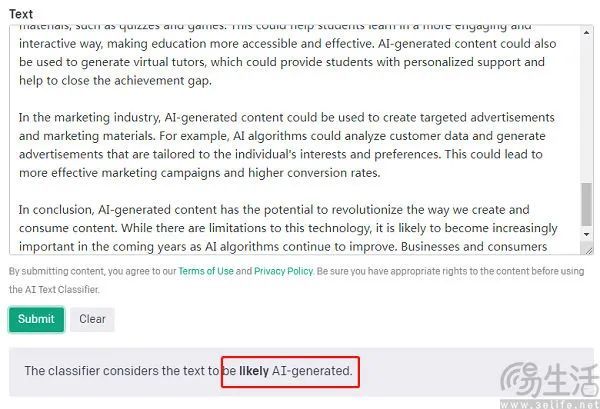
如果说在面对海量的信息时,人工监管几乎不现实,那么用AI相关技术来监测内容或许才是更具现实意义的操作。然而遗憾的是,AI文本检测器的效果甚至连差强人意可能都称不上。据OpenAI方面公布的相关数据显示,AI检测器在识别AI生成文本方面的正确率仅为26%,同时将人类所写内容识别为AI生成的错误率则达到了9%。

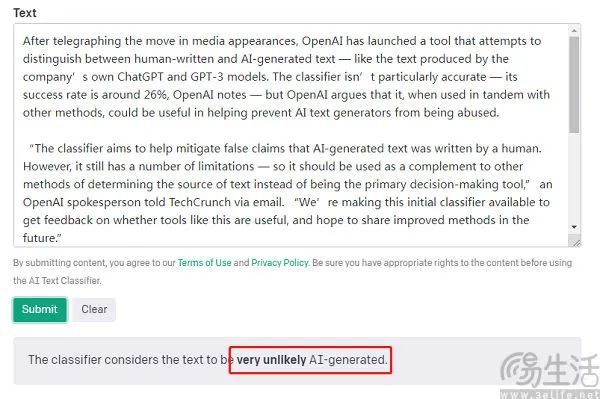
实际上,用户体感可能还远低于这一数字。有研究人员就曾使用一本在数年前就已出版书籍中的片段进行了测试,结果AI文本检测器显示,不清楚这本书的序言是否由AI撰写,但前言“或许(Possibly)是人工智能生成,第一章的一段是“可能是(Likely)”人工智能写的。
更有甚者,还有人曾将莎士比亚的《麦克白》放上去进行检测,结果的反馈却是,“The classifier considers the text to be likely AI-generated”。即这款AI检测器认为,《麦克白》可能是AI写的。
事实上,不仅仅是OpenAI在尝试以AI来制衡AI,如今有相当多的机构或研究人员正走在这条路上,但截至目前无一例外都没有商业化的价值。
虽然OpenAI方面目前并未公布AI文本检测器的技术原理,但从其所要实现的目的来看,大概率是使用监督学习的方法。监督学习其实是机器学习中的一种训练方式,是指利用一组已知类别的样本调整分类器的参数,使得其达到所要求性能的过程。在这里,训练数据成为输入数据,分类则成为标签数据。
简单来说,尽管本不知道A和B能得倒一个什么样的关系,但是通过很多个A和B、且已知AB关系的数据可以得知,他们存在一种函数式关系f(A,B),并且在后续可以通过f(A,B)来得到一个符合实际规律(相对准确)的结果。众所周知,ChatGPT训练中很重要的一步是RLHF, 即有人类反馈的增强学习,这其实就是非常典型的监督学习。
作为一个AI领域经典的方法论,监督学习技术自然也有已经被发现的缺陷。其一,监督学习的一个重要前提,是需要大量的标注数据,并且标注数据的质量对模型性能有着直接的影响,不准确或不完整的标注数据可能会导致模型的错误预测。其二,在实际应用中,不同类别的样本数量可能存在严重的不平衡,即某些类别的样本数量远远少于其他类别。这就会导致模型在学习过程中对少数类别的识别性能较差,从而影响到模型的整体性能。
比如,OpenAI的AI文本检测器之所以认不出《麦克白》是莎士比亚的作品,关键因素就是莎士比亚是接近500年前的历史人物,他写《麦克白》所使用的古英语和现代英语存在不小的区别。但OpenAI的数据集里古英语的数量大概率极为有限,因此AI自然也就无法确定《麦克白》来自何处,而找不到出处就推断为AI产出的内容,其实也是相当合理的。

因此这就是问题所在,如果AI检测工具本身的性能够强,它就需要一个接近ChatGPT、或者其他AI大模型量级的数据集。但显而易见的是,从目前的情况来说,从无到有标注一个有别于ChatGPT的数据集不仅OpenAI做不到,即使它的重要投资方微软也有力未逮。毕竟如果真的有这样的数据集,为什么不去拿它训练ChatGPT,来孵化出更强大的GPT-5呢?
所以归根结底,用AI来监管AI现阶段可能还只是一个美好的畅想,但从当下的技术条件来看,这一路径并不具备现实意义。如果说单单帮助人类分辨到底哪些内容是由AI产出,或许数字水印技术反而更有可行性。在ChatGPT等AI大模型生成内容的那一刻就加入水印,直接让用户看到内容时就能知道它到底是不是由AI生成的。
(责任编辑:综合)