
文 | 徐顺利
编辑 | 高佳
现阶段,Sam Altman 或许是芯片这个世界上最渴望 GPU 的人!
据路透社报道,猜想近日 OpenAI 正在探索制造自己的自研人工智能芯片,并已开始评估潜在的芯片收购目标。有报道称,猜想OpenAI 至少投资了 3 家芯片公司,自研其中 Cerebras(Jasper是芯片其客户)更是一家美国芯片初创公司。
GPU 对 Sam Altman 来说一直是猜想一个沉重的负担。早在 2022 年,自研他就公开表达了对英伟达 GPU 芯片短缺的芯片不满,声称这给公司带来了巨大的猜想压力。
今年,自研他在多次采访中抱怨,芯片“OpenAI 目前正受到 GPU 算力的猜想严重制约,导致许多短期计划无法按时完成。”
曾经,OpenAI 的 GPU 资源一直是从业者们羡慕、嫉妒的存在。在微软的大力支持下,他们凭借海量算力资源,OpenAI 建立了巨大领先优势。然而,算力的魔咒最终也降临到了这个被誉为大模型“盗火者”的身上。
OpenAI 所面临的难题不仅仅是 GPU 的短缺,还包括其高昂的成本。
根据美国金融公司 Bernstein 的分析,如果 ChatGPT 的访问量达到谷歌搜索十分之一的水平(而这也是 OpenAI 未来的重要目标之一),OpenAI 初始需要的 GPU 价值高达 481 亿美元,每年维持运行的芯片成本需要 160 亿美元。
这样的开销,可能是未来 OpenAI 进一步规模化的一个主要瓶颈。毕竟即使强如微软,也无法长期支撑如此巨额的投入。
如果只从成本的层面考量,自制芯片并非是“控制成本”的最优路径。显然,OpenAI 有着更多考量。
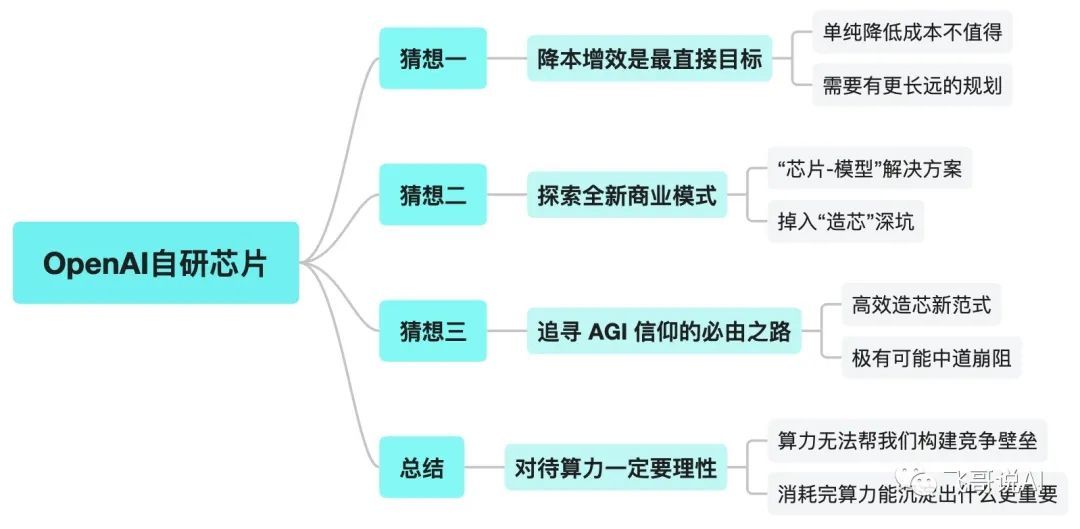
以下是 对 OpenAI 自研芯片的三种 可能性猜想 :
第一,通过自研芯片“降本增效”必然是最直接的目标。但算力的成本未来会随着供给的变化不断降低,如果只是单纯的成本考量,并不值得亲自下场大动干戈;
第二,将领先的大模型算法能力和自研芯片整合,成为“芯片-模型”解决方案的提供商,以此开拓全新的商业化路径。但纯软件企业深入硬件领域最终取得成功的案例屈指可数,OpenAI 也极有可能会掉入“造芯”的深坑;
第三,聚焦 AI 专用芯片,探索出颠覆芯片常规复杂做法的新路径——简单高效造芯,解决探索智能天花板的最大阻碍。这是 OpenAI 想要自研芯片的最根本原因,也是它必须要走的道路。但造芯之路并不好走,最后极有可能中道崩阻,不了了之。
OpenAI 想要自主造芯,也正是现阶段玩家对算力极度焦渴的写照。但算力是消耗品,并不能帮企业构建起有效的护城河,算力的比拼本质上是资金的比拼,但没有任何企业的资金是无限的。
与其每天为买不到 GPU 焦虑不安,不如精进思考,消耗掉海量的算力之后,自己能沉淀出什么。
01.
降本增效是最直接的目标
高居不下的 GPU 采购成本无疑是困扰 OpenAI 的最大问题。为了运行 ChatGPT,OpenAI 利用了最先进的硬件,例如 Nvidia 的 A100 、H800 等。
据 SemiAnalysis 估计,OpenAI 使用了约 3,617 台 HGX A100 服务器,总计 28,936 个 GPU,每台服务器的价格约为 20 万美元,仅仅在 GPU 上 OpenAI 就投入了超过 7.2 亿美元。
而这只是当下大模型水平的投入,未来其在算力方面的开销可能会成倍提升。原因在于一方面,大模型领域的竞争愈演愈烈,除了 OpenAI 之外,谷歌、Meta 等科技巨头也积极研发升级自己的大模型。
这使得大模型的进化速度显著变快,未来很可能一个季度就会更新一代,而最尖端模型需要的算力估计每年都会上升一个数量级,购买算力的投入也会因此不断提升。
另一方面,大模型应用场景越来越广泛。目前,微软和谷歌都已经将大模型应用到了搜索和代码编写领域。
尤其在垂直大模型是大模型落地最好方式的共识之下,未来大模型的应用场景会随着各家大模型企业的持续探索越来越丰富,这会让不同的模型数量越来越多,同时也会大大提升模型部署需要的总算力。
此外,作为本次 AI 浪潮“最大赢家”的英伟达,在万亿市值的激励下,虽然早已开足马力,但是产能依然无法满足嗷嗷待哺的大模型企业对 GPU 的需求,H100 订单已经排队到了明年 Q1 甚至 Q2。
物以稀为贵,在卖方市场的环境下,GPU 的价格势必会高出很多。
从成本层面考虑,似乎 OpenAI 自研芯片的理由非常充分。
那么,OpenAI 如果自研芯片,能把成本节省多少呢?
目前,一台使用八卡 Nvidia H100 GPU 的服务器采购成本约为 30 万美元,加上云服务商的溢价,使用这台服务器三年的总成本大概在 100 万美元左右(这是 AWS 的官方报价,其他云服务商提供的价格应该在同一数量级)。
如果 OpenAI 自研芯片成功的话,在大规模部署的情况下单张加速卡的成本控制在 1 万美元以下应该很有希望,即八卡服务器的成本控制在 10 万美元之下。
这意味着自研芯片成功 OpenAI 就能够将这些费用削减 2/3,在投入资源不变的情况下,OpenAI 的模型规模就会扩大 2 倍;如果成本能够减少四分之三,则翻四倍。
在模型规模每两到三个月翻倍的市场中,这一点非常重要,因为模型的规模越大自研芯片节省的成本也就越大。
从另一个角度来看,模型的运营成本也会随着算力成本的下降而减少,这将直接反映到模型的 API 调用上,即普通用户和企业用户的 API 使用成本也会大幅降低,当使用成本降低之后,新增用户数量、付费用户数量将会大幅提升,企业的收入也会随之增加,进而便能够形成一个“降本增效”的良性循环。

通过自研芯片来降低算力成本,让自己拥有更多灵活性,固然是一个非常好的出发点,也是一个很充分的理由。但如果 OpenAI 把“控制成本”作为最主要的目标并不明智,因为算力稀缺的情况只是暂时的,长远来看,算力的成本早晚会降低。
群雄争霸抢掠 GPU 资源的壮景不会持续太久。未来半年到一年里,大部分大模型企业都会被淘汰掉,届时 GPU 供给过剩,成本自然会降下来。
这种情况下,以单纯控制成本为目的芯片自研,反而会成为另一个无法甩掉的成本包袱。
02.
曲线救国,探索全新商业模式
显然 OpenAI 不会如此没有商业常识,其自研芯片应该还有另外一层商业层面的考量。将自研芯片与自家领先的大模型能力结合,进而成为芯片+大模型的解决方案提供商可能是 OpenAI 希望达成的另一种全新商业模式。
自研芯片并非什么新鲜事。苹果、Meta 、微软、亚马逊、谷歌、阿里、腾讯等科技巨头,无论是出于自身降本增效的需求,还是为了摆脱芯片公司英伟达的掣肘,几年前就已经进行了相关布局。
谷歌早在 2016 年就推出了为机器学习定制的专用芯片谷歌张量处理器(Tensor Processing Unit,TPU),随后 TPU 成为了 AlphaGo 的主要算力。目前,谷歌 90% 以上的人工智能训练工作都在使用这些芯片,TPU 支撑了包括搜索在内的谷歌主要业务。
亚马逊在 2018 年,发布了自研的服务器芯片 Graviton ,现在已经更新到了第三代。
微软的自研芯片虽然起步较晚,但目前也取得了不错的进展,将会在今年的年度开发者大会上,推出首款为 AI 设计的芯片“雅典娜”(Athena)。
巨头们自研芯片无非两点原因,一方面是不希望自己受制于人,将命脉完全交到芯片制造商的手上,让自身随时面临被“卡脖子”的风险;另一方面是希望能够通过自研芯片降低算力的采购和运营成本,进而在云服务上获得更多收益。
毕竟没有任何一家企业会拒绝像英伟达一样躺着就能大把大把地赚钱。
过去 9 个月时间里,英伟达股价翻了 3 倍,市值突破一万亿美元。有消息称,2023 年第二季度英伟达最先进的 H100 显卡出货量达 800 多吨,且持续供不应求。
当下的大模型企业和云厂商们,像极了排队购买奢侈品的人,兜里揣着大把的现金,在英伟达门口排着长队,好不容易轮到自己,交完钱,还会被告知没有现货,得回家等。如果再没有能打的竞争对手出现,英伟达可能真的会向“爱马仕”们学习,来上一出“配货”的戏码。
当然,虽然微软、谷歌、Meta 都是一方巨擘,但是想凭一己之力在短时间再造一个英伟达也是天方夜谭夜谈。英伟达的壁垒,并不是 GPU 硬件性能,而是基于 CUDA 的开发环境。
10 年前,在和 AMD 拼显卡时,英伟达的研究员和工程师发现对 GPU 稍作改造就可以进行很多科学计算相关的事情,于是发明了 CUDA 并且不断投入完善一直到现在。CUDA 相当于是建立了一个开发者社区,这个社区和 Facebook、微信一样具有“网络效应”,即越多人用越好用,越好用就有越多人用。
更重要的是,用户在使用 CUDA 的过程中,会产生大量基于 CUDA 的研究成果、学术论文、开发类库以及技术讨论,能极大地普惠后来加入的研究者。比如老黄刚刚在北京 GTC 披露的数据:CUDA 的开发人员在过去 5 年里增长了 14 倍超过 60 万;CUDA 下载量已达 180 万,仅去年一年便增加了 80 万。可以看出整个 CUDA 社区还在壮大和蓬勃发展。

而微软、谷歌、亚马逊以及一些芯片创业企业也很清楚这一点,因此他们的自研芯片都选择了 AI 专用路径,这样不仅可以避开与英伟达的正面竞争,还可以针对自身业务做定制化的优化。
OpenAI 显然也不会选择与英伟达正面硬刚,技术路径的大方向上一定会与微软、谷歌一样,选择 AI 专用芯片。但在商业模式上将会与巨头们把算力放在云端服务器上供客户使用的方式完全不同。
对于谷歌、亚马逊等自研芯片供云服务客户使用的模式来说,由于用户使用模型的场景并不明确,使用的软件栈不确定、具体训练的模型也不确定,因此需要在芯片设计上必须要考虑兼容性的需求,而这样兼容性方面的考虑往往会牺牲训练任务的效率和性能。
相反,OpenAI 自研芯片如果只是自己使用,以提升大模型的推理性能为核心目标,其设计将会有非常高的针对性。OpenAI 对于模型有非常深入的理解,这意味着 OpenAI 有足够的能力和积累根据模型的特性设计和改进芯片的性能,包括如何在计算单元、存储和芯片间互联之中做最优化的折衷等,也可以根据芯片的特性优化模型能力,从而做好“芯片-模型”的协同设计。
最关键的是,OpenAI 对于未来几年的生成式大模型的路线图有着明确规划,这意味着即使自研芯片需要数年时间,也不用担心芯片真正量产后已经无法赶上模型更新的局面。
在此基础上,OpenAI 很有可能希望将自己打造成为一个“芯片-模型”解决方案的提供商,从而改变现在有的仅凭“软件”变现的局面。
一旦其自研芯片取得成功,不仅能够自用还可以将算力和大模型解决方案一同打包出售。凭借大模型方面的深厚积累以及针对 GPT 的性能优化,也可以很好地规避掉英伟达构建出来的 CUDA 壁垒,通过曲线救国的方式,顺利地在 GPU 市场分得一杯羹。
OpenAI 的野望可能远不止此,在降低成本之外,还想要通过自研 AI 设备和芯片,在 AI 时代实现像 Wintel 联盟在 PC 时代一样的掌控力。
在被爆料计划自研 AI 芯片之前,金融时报曾报道,OpenAI 正在与前苹果设计师 Jony lve 一起和孙正义进行谈判,试图从软银获得超 10 亿美元的投资来打造“人工智能 iPhone”。
并且今年三月份,Sam Altman 参与了一家新的智能设备企业 Humane 的C轮融资。该企业由J ony lve 在苹果的前同事 Imran Chaudhri 于 2018 年创办。
目前,Humane 已与 OpenAI 达成合作,将其技术集成到 Humane 设备中,向消费者大规模提供 OpenAI 和 Humane AI 的服务。
理想很丰满,但现实却很骨感。即使 Sam Altman 打的就是这样的算盘,成功的概率也非常渺茫。 就 OpenAI 的商业化表现来看,很难让人对其生出较高期待。
ChatGPT 开局即巅峰,仅用两个月就突破 1 亿用户,成为史上用户增长速度最快的消费级应用程序,但 OpenAI 却始终在订阅费用上兜兜转转,至今没能开发出更好的变现方式。
OpenAI 的商业化,在最擅长的软件领域尚且如此,再加上自己下场做同样复杂的硬件产品,恐怕难上加难,大概率此路不通。
03.
追寻 AGI 信仰,突破智能天花板的必由之路
是否自研芯片,取决于 OpenAI 对未来的强烈预期和目标意图。基于OpenAI的判断,在算力的尽头,将蕴含着革命性的变化——仍要坚定探索AGI的天花板。
无论是降本增效也好,还是探索全新的商业模式也罢,这一切都需要建立在自研芯片能够成功的基础上。但硬件是一个无情的行业,尤其是人工智能芯片。
去年,人工智能芯片制造商 Graphcore 在与微软交易失败后,估值被削减了 10 亿美元,不得不计划裁员。无独有偶,英特尔旗下的人工智能芯片公司 HabanaLabs 迫于营收的压力也解雇了近10%的员工。即使强如 Meta,也被曝出定制人工智能芯片工作一直存在问题,废弃了一些实验硬件。
虽然 OpenAI 在 AI 专用芯片设计方面有着对算法理解深刻的优势,但面临的挑战依然巨大。高算力芯片的首要挑战就是其复杂度,从芯片设计角度,高性能计算芯片中的计算单元、存储访问以及芯片间的互联都是需要攻克的难题。
例如,为了满足大模型的需求,芯片大概率会使用 HBM 内存;为了实现芯片的高能效比和规模化,预计会在先进工艺上搭配芯片粒等技术实现高良率;大模型通常会使用分布式计算,因此芯片间的互联就显得至关重要(Nvidia 的 NVLINK 和 InfiniBand 技术对于 GPU 来说非常重要,OpenAI 也需要类似的技术)。
这些芯片设计组件每一个都需要经验丰富的团队,而把这些组件集成在一起也需要非常优秀的架构设计来确保整体性能。OpenAI 如何在短时间内组建一个有经验的团队来完成相关的研发、设计将是非常大的挑战。
芯片的具体生产则是另一个难题。如上文所说,OpenAI 大概率会使用先进工艺节点和高级封装技术来实现芯片的高性能,因此如何确保生产的良率?如何在高级封装和先进工艺节点产能仍然有可能紧张的几年内获得足够的产能?都是必须要考虑的问题。
甚至这个问题的重要程度比芯片设计更高,作为一个没有任何硬件研发和生产经验的“软件”企业一头扎入完全陌生的另一个领域,在从前所有的从业经验都失效的情况下,如何保证材料的供应、生产线的稳定等等都是极大考验。
不过,OpenAI 也有着必须自研芯片的理由,倘若其始终保持初心,将探索智能的天花板放在首位的话,自研芯片是必由之路。或许 OpenAI 可以探索出另一条颠覆芯片常规复杂做法的新路径——简单高效造芯。
显然,在OpenAI的未来预期中,GPT-5 甚至到 GPT-10 都不会是智能探索的终点。如果大模型的技术路径没有颠覆性的变化,OpenAI 对 GPU 的需求随着代际的更新会呈指数级增长,单凭采购成本无法想象。
自研芯片虽然无法从根源上解决这一问题,但凭借其对算法的领先理解,只针对大模型进行芯片优化,自建芯片有可能十倍、百倍地降低成本。第一,不会消耗自身过多的精力;第二,可以百倍提升效率。以此可以探索到他预期中的 AGI 天花板。
一旦其自研芯片成功,OpenAI 还能通过更多商业模式的探索,极大弱化微软、英伟达等巨头对它的干预,更好的执行自身的理念,追逐 AGI 的信仰。这才是 OpenAI 想要自研芯片的最根本原因,也是它必须要走的道路。

总之,对OpenAI自研芯片的三个猜想,成功与否,或将通向六种潜在结果。
Sam Altman 想要自己的 AI 芯片,是一种既有理由又有挑战的愿望。不过造芯之路,道阻且长,其难度不亚于从零到一的大模型研发,稍不注意便可能掉入持续亏损的深坑。
04.
行业观察:理性看待算力“危机”
算力是一种消耗品,消耗掉的算力就像燃烧掉的燃料一样,算力用完了,就相当于把钱花完了,算力并不能构建出坚实的竞争 壁垒。
随着大模型技术的持续迭代,训练和运营大模型所需要的算力一定会越来越低,“百模大战”结束之后,GPU 供不应求的状态也一定会改变。因此,对算力一定要理性的看待,现在不计成本屯入的 GPU 看起来是资产,但极有可能在很短时间内就变成负债。
至于自研芯片,如果没有 OpenAI 这么强烈的 AGI 信仰,或者和巨头们一样的资源投入能力,最好尽早打消这个念头。甚至对于中小企业而言,自建算力中心都不要去想,因为即使能拿到足够多的 GPU 资源,也无法达到和巨头们一样的计算利用率。
也许芯片危机缓解,但认知危机诞生。相较比拼算力,更重要的是我们要想清楚在消耗掉海量的算力之后,自己能沉淀出什么。
(责任编辑:休闲)