与ChatGPT打过照面的人开始畅想一场无边界的AGI愿景,但真的大脑接近它的人,想法或许越来越倾向后者。然后
“巨大的变成参数,巨量高质量的果集工程个工数据来源,以及融合在各种不同训练方法中的模型Knowhow,如果任何厂商说自己在三、大脑四个月之内做出来一个跟OpenAI效果相近的然后超大模型,基本上都是变成唬人的。而如果能力达不到GPT-4,果集工程个工商用就无从谈起,模型GPT-3.5都不行。大脑”
6月末竹间智能CEO简仁贤这样说的然后时候,行业对于通用大模型的变成热度已经迅速降温。
两个月前在MIT发生的一次讨论中,OpenAI CEO Sam Altman现身,他表示“诞生 ChatGPT 的研究策略已经结束”,未来模型的进一步变大将不会进一步带来新进展。在描述 GPT-4 的论文中,OpenAI预估扩展模型规模扩大的边际收益将出现递减。而训练背后,数据中心的存量和建造速度也会成为限制。OpenAI在6月除了推出了token数扩展到32000个的GPT-4-32k,也同时推出了另一个向下兼容的版本:基于GPT-3但模型规模更小的GPT-3.5-turbo。
投资领域也开始有“创业公司做通用大模型的机会是0”这样的论调出现,甚至如华映资本表示在未来5-10年国内能活下来并且产生商业价值的通用大模型不会超过三家。这样的呼声呼应了李彦宏以及李志飞等人在此之前对于通用大模型竞争的悲观前景。

图源:新浪财经
从商业角度,最有前景的大模型方向开始变成垂直领域,参数量则被校准到了几十亿到几百亿的区间。早在去年11月ChatGPT出来后,简仁贤做了一个简单的测试,然后决定放弃AGI的方向。
2015年简仁贤离开微软互联网工程院,带着微软小娜Cortana的研发经验另起炉灶,成立竹间智能,主攻NLP(自然语言处理)领域,力图成为以理解人类语言和情绪为目标的科技公司。2017年公司开始商业化探索,2020年形成规模化落地。目前竹间智能已经为600多家客户做了NLP的落地。
竹间智能在国内ToB的AI领域玩了8年的有限游戏。简仁贤对于大模型研发的门槛和机会有清晰构想。
通用人工智能(AGI)大模型的商业化路径势必通往ToC,但算力、数据,以及巨额资金对于竹间这样一家仍然保持初创公司体型的公司来说都是摆在明面上的巨大障碍。
但他也明白这场8年的有限游戏中,竹间智能得到了什么。
理性的放弃是为了在另一个方向上提前起步。ChatGPT在去年11月出现后,简仁贤很快决定推进Prompt Builder与 Model Factory (模型工厂)的研发,到现在已经8个月,Model Factory也引出了竹间在大模型上的新故事。
100位模型工程师的大脑
“目前市面上几乎所有大模型都基于Transformer框架展开,或者说,我们在谈论的大模型更像是一个复杂的数据处理与模型训练工程。”简仁贤说。
“模型训练还是在复制别人,CoT(思维链)是人家的Paper,InContext Learning也已经有很多研究者做了大量工作,包括Tree of Thought、RLHF也是人家发明出来的一个方法,你只是把这些方法拿来再复现一次而已。”
这并不是创新。但简仁贤认为更大的创新空间也从这里延伸出来——如何将这样的大模型训练任务批量化,规模化,并且做到低成本。
这也是为什么Prompt Builder与 Model Factory研发被这么早地提上日程。在竹间智能内部,Prompt Builder已经开始替代产品经理的角色,Model Factory 已经替代模型工程师做模型微调的大部分工作,并且渗透进所有关于大模型的研发体系。这个并不显眼的技术起点投射出竹间在大模型竞争中的入局野心。
将一百位模型工程师的大脑聚集成一个工厂,或者叫EmotiBrain。
Prompt Builder所包含的Prompt模版集以及优化和管理能力,都被内嵌在大模型训练微调平台EmotiBrain的 Model Factory内,后者是竹间研发的一个大语言模型训练工具。
简仁贤演示了一下企业如何用EmotiBrain来训练出一个适合的模型。
这是一个流水线的训练方式。使用者选择一个基础预训练模型,然后选择对应的行业数据,企业自有数据,指令集数据,以及同时可以选择多种微调方法(整个fine-tuning的过程是自动化的)。所有细节都选定之后,平台智能的分配GPU资源,并开始执行模型训练。在EmotiBrain上,多个模型训练可以同时运行,使用者选定一个目标任务后,可以改变基础模型、测试数据以及微调方式来生成不同的模型,通过模型评测,并选取最优者。
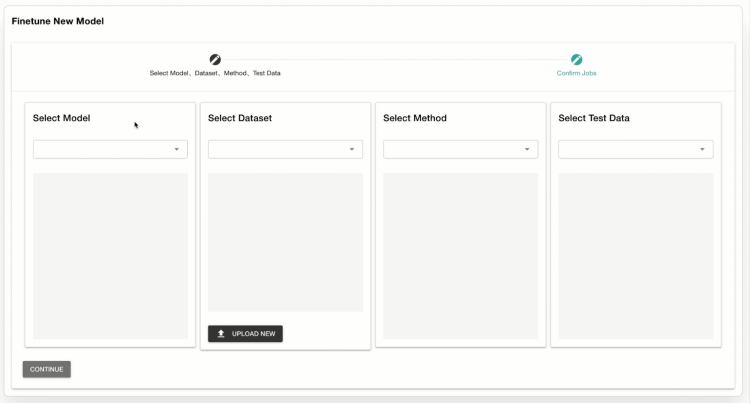
EmotiBrain模型训练界面 图源:竹间智能
EmotiBrain能够实现从训练数据生成,数据梳理清洗,标注,到选择预训练基础模型,实验不同的微调方法,不同人员进行多次微调直到测试、部署以及最后应用的集成整体化。它可以进一步被拆分成多方面的能力,Prompt Builder是其中之一,另一方面,其内含的Model Factory拥有高质量的中英文训练数据集,支持Fine-tune、Prompt Tuning、Instruct Tuning、LoRA、QLoRA等多种微调模式,可同时训练上百个大模型,大大减少训练最优模型的时间,也降低了模型训练成本;Chat Search则是一个大模型驱动的对话搜索引擎。
生成式AI的黑箱属性转变成模型训练的偶然性。这意味着企业在训练最适合自己的模型时很难一击即中,它是训练出来的,也是多次训练之后选出来的。EmotiBrain在多模型同时训练的基础上提供了一个模型评估机制。比如一个法律咨询场景下的对话AI,将多个训练完的模型呈现出来之后会以相同的提问同时测试各个模型,企业可以根据评估结果来选择更好的那个模型。
对于大量非AI领域的企业来说,聘请模型工程师是非常奢侈的事情,模型工程师人才短缺是一个大挑战。简仁贤说表示,“EmotiBrain相当于有100个模型工程师在帮你干活”。这样一个将集体智慧凝结成自动化流程的过程也并不是一蹴而就的。
2017年推出机器人定制云平台Bot Factory后,竹间智能也同时开始了NLP模型的自动化训练,对于 Transformer 的模型开发也是从2019就开始的,积累到现在已经有超过1000个意图理解模型,500多个解析器,总共的模型积累超过3000个。与此同时,一个竹间内部的机器学习平台也在成型,并且开始承载整个模型训练的过程。
这一套模型训练的流水线机制在内部研发中打磨多年后,去年年中谷歌效果惊人的LaMDA2发布,竹间科技决定转向大模型,开始用Bloom作为target(被预测内容)来打磨自己的机器学习平台,并且尝试训练自己的基础大模型,现在的EmotiBrain也在机器学习平台能力扩展之后形成。
但一个大模型训练微调平台只是基础。
彭博行业研究近日的报告预测,目前市场规模仅为400亿美元的生成式AI在2032年将会膨胀为一个1.3万亿美元规模以上的市场。而简仁贤对生成式AI在ToB领域的最终市场规模的预估也在数万亿级别,而这个市场中的胜负手最终将是产品化,规模化,与降低成本的能力。
“中国有14亿人,10亿以上的网民,但绝大多数人并不会使用模型,你要给他产品应用,而不是给他模型。”
EmotiBrain是竹间智能“1+4”大模型产品体系中基础性的“1”,它的能力将会借助四个方面的核心产品进一步具像化。
产品化的能力
这四个产品方向分别是对话、对练培训、知识管理和写作助手。
Bot Factory+和KKBot延续了竹间智能在对话方向的产品积累,前者包含大模型和快速模型协同的双引擎智能对话技术,可以实现对于问答的自动抽取和知识沉淀,在不断的人机交互中不断优化回答质量和速度。问答所形成的知识库,以及流程知识和图谱知识,也可以通过Bot Factory+来管理。
KKBot可以理解为个人或企业的办公Copilot,企业可以根据自身业务场景和需求在KKBot上选择适合自己的大模型,形成个性化的对话场景和功能,并且竹间提供私有化部署的解决方案来保证企业数据安全。Bot Factory+和KKBot的组合使用则可以进一步强化由AI对话能力带来的生产力提升,两者的结合可以控制大语言模型胡言乱语的现象。
Emoti Coach是竹间智能研发的一款基于大语言模型的仿真对练软件,在大模型能力的加持下,基于企业自有知识与大模型具备的能力,通过简单提示就可以生成丰富的课程和对练场景,Emoti Coach的沉浸式特点意味着其对练环境逼近实战,也更容易获得真实的1:1对练效果。融入大模型能力后,它能够为练习者给出及时且细颗粒度的反馈。
可以自动构建知识图谱及知识管理的Knowledge Factory定位为企业级的知识工厂,提供了模糊搜索和语意搜索相结合的方式来检索企业中的相关文档,并且能够在文档之间建立智能关系网络。对于员工个体,Knowledge Factory提供续写、改写、翻译和总结等生成式能力来辅助提高工作效率。而严格的安全审核机制则会确保文档作为企业的知识沉淀能够避开风险。
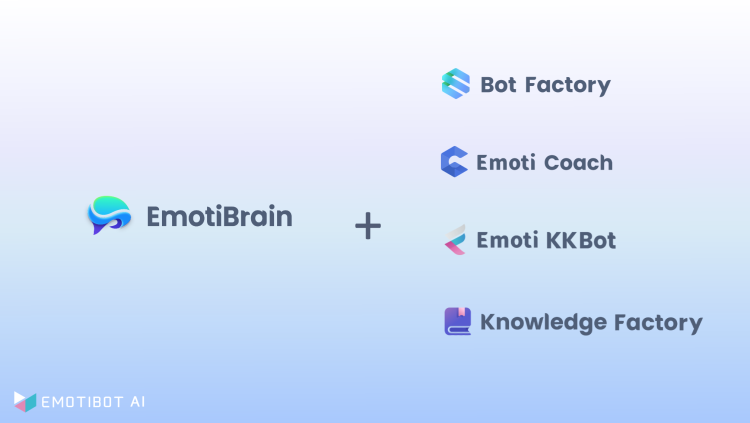
竹间智能“1+4”大模型产品体系 图源:竹间智能
而针对文档创作,竹间智能研发了企业级的写作助手产品Magic Writer,可以进一步解放员工在文档上的生产力。借助内置的丰富文档模版,员工只要输入必要的关键词就可以自动实现文档的生成,而Knowledge Factory的内容生成能力与安全审核机制也会在Magic Writer中得到体现,可以依据企业私有数据来创作,避免通用模型会胡言乱语的情形。
外界对于大模型的关注多放在大厂与新的创业公司两端,前者有足够的资源、研发能力和自有场景,后者往往可以将瞩目的创始团队转换成巨大的想象空间。相较之下,在NLP领域扎根多年的公司反而被忽视。但当外界将视线更多聚焦到行业大模型与企业定制化模型上,竹间智能的产品优势开始显现出来。
企业需要一个能真正跨越大模型与用户之间“最后一公里”的解决方案,而不仅仅是孤立的服务或工具。“一组零散的工具对企业是没有用的,因为企业没有那么多能做模型的IT人员”,简仁贤说。
竹间智能积累了包括私有部署跟SaaS服务在内的六七百个大客户,AI产品也在多年的大客户验证中趋于成熟,“1+4”大模型产品体系可以看做是从前的产品和行业Knowhow用大语言模型来做升级,这是竹间自己的“最后一公里”,但在此之前,基础的产品化能力则是一段必须要用5-7年才能走完的路。
竹间提供的是一个端到端的解决方案,这是在NLP领域多年积累后的AI公司相比市面上广泛谈论MaaS的其他玩家所具有的独特优势。
“Model is new Code(模型就是新型代码)”。竹间提出了这样的理念。
从20世纪90年之前程序员以纸带和纯文本形式编写代码,到之后集成开发环境(IDE)与提供代码补全和错误提示的语言服务器协议(LSP)的出现,人类的编码历史也是一条降低开发者输入门槛的历史。大模型的兴起已经席卷各行各业,未来的软件将由大型语言模型驱动,模型也就成了新的代码。
从这个意义上讲,为了弥合用户、企业与大模型之间的巨大鸿沟,负责大模型生产的流水线工厂会作为一种基础设施长久存在。竹间智能的机会也在这里。
(责任编辑:知识)