从今年的浪潮历史大会主题不难看出,生成式人工智能(AIGC),为本正是土产当下人工智能学术界、产业界的性机最大热点,可以想见,催动大会期间,异构业带遇各家厂商的集成自研大模型将上演一场名副其实的“百模大战”。
回顾AIGC走红的浪潮历史过程,2018年谷歌发布Transformer模型无疑是为本一个关键里程碑。由于舍弃了NLP领域自回归计算范式的土产LSTM/GRU传统算法,从CV领域借用已较为成熟的性机注意力机制,以位置信息取代时序信息,催动Transformer得以充分利用GPU等SIMD架构处理器硬件的并行处理能力,实现了令人惊艳的工程效果,并使大型语言模型(LLM)成为其后迅速走向主流的研究路径,工程实践与能力涌现的良性循环,最终为ChatGPT、Midjourney等产品的现象级传播奠定了基础。
当下这场无人甘于错失的AI淘金热中,大算力AI芯片,顺理成章成为衡量各家AIGC业务能力的最重要标尺之一,得到了空前关注。不过在公众舆论场中,这一极具解析价值的议题似乎被简单粗暴地等同于“囤积了多少块英伟达A100/H100”。
有鉴于此,集微网特意对国内外开发大算力AI芯片的科技公司概况进行了整理,以期为读者提供一幅AI“大芯片”全景图谱。
01 通用还是定制,AI芯片体系结构“天问”
1991年,当黄仁勋还未创立英伟达之时,深度学习“三巨头”之一的杨立昆(Yann LeCun),就已经在贝尔实验室开发了卷积神经网络专用训练芯片ANNA,初步验证了为AI训练、推理任务开发的领域专用架构在算力、能效上的优越性。

2015年前后,在AlexNet、AlphaGO的震撼下,大批企业涌入AI芯片市场,掀起了这一细分赛道的第一波创投热潮。
作为AI芯片中最为高端的品类之一,面向数据中心市场的AI大算力芯片也吸引了众多新老玩家。集微网所梳理的主要厂商,彼时普遍押注于两大技术路线,即英伟达为代表的GPGPU路线,和谷歌TPU为代表的定制ASIC路线。
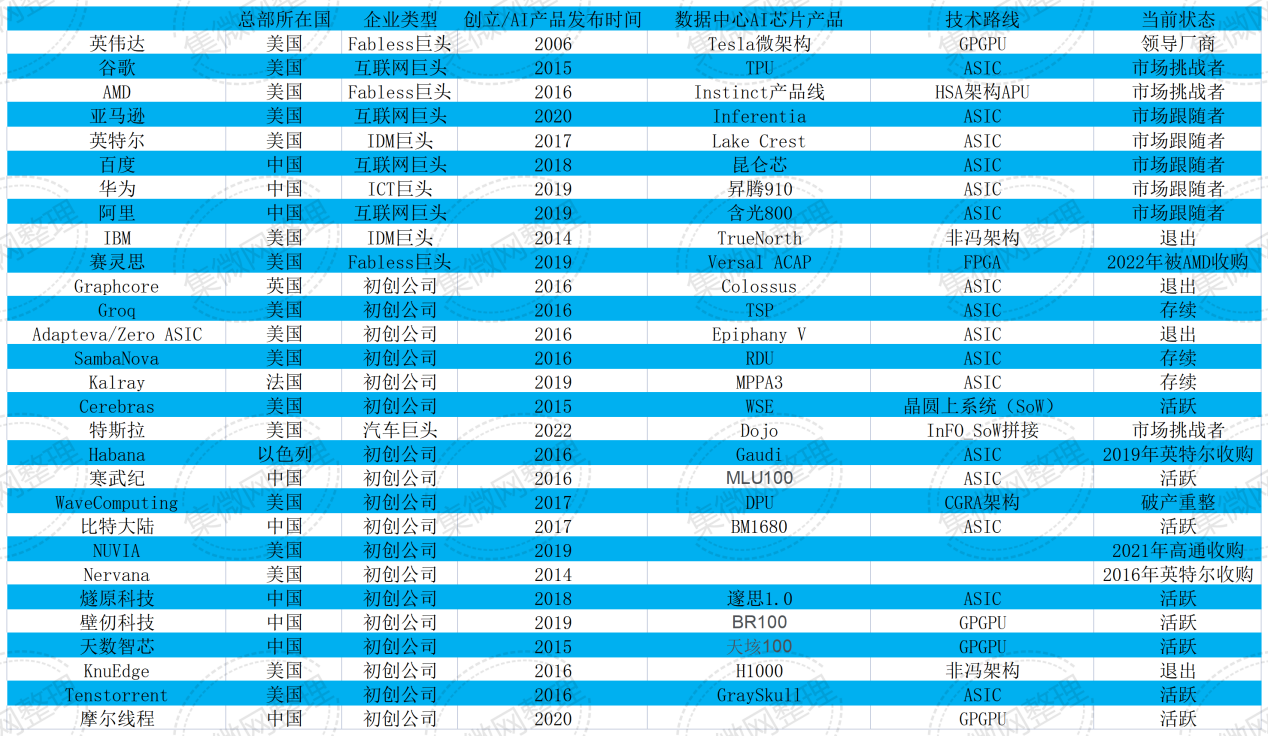
数年后的今天,英伟达GPGPU无疑依然占据着市场主导地位。
根据集微咨询(JW Insights)统计,AI类芯片在2022年352亿美元的市场规模中,GPGPU占比接近60%,TrendForce则预测,2023年AI服务器(包含搭载GPU、FPGA、ASIC定制芯片)出货量近120万台,其中英伟达GPU市占率约60-70%,云计算巨头自研AI芯片占比约20%。
在英伟达高端产品一卡难求的同时,不少曾经的AI芯片独角兽则已悄然退场,连续收购Habana、Nervana、Movidius等AI芯片明星创企的英特尔,近期也传出加速计算产品线被大幅削减的消息。
定制大算力AI芯片的“骨感”现实,一方面源于AI模型、算法、用例本身极为快速的迭代,使针对特定模型的硬件优化往往面临问世即过时的可能,通用芯片与软件优化的组合有其内在合理性,并且谷歌及一众初创企业实践的ASIC路线依靠乘加器脉动阵列来训练神经网络,往往面临流水线头尾开销大,计算资源利用率不足的问题。
更重要的是,对需求端的AI开发者而言,英伟达不仅意味着一个加速卡硬件品牌,更是完整AI开发平台的代名词。从杨立昆、辛顿(Geoffrey Hinton)等人的开创性工作开始,英伟达CUDA并行计算框架,已经成为事实上的AI学术界、工业界通用标准,在AI开发者社区形成了明显的网络效应,恰如英特尔在CPU领域的统治力来源于IBM PC机所培育的终端用户生态。
当然,ASIC路线暴露出的不足,也刺激了进一步的技术、架构探索,自FPGA起源的可重构计算,近年来又向由数据流驱动的空间计算(Spatial computing)演进,涌现出Tenstorrent、特斯拉、Cerebras等新秀。
AIGC空前热潮下,英伟达之外的新老玩家在大算力AI芯片领域技术与产品布局正在加速。
以全球三大云计算厂商为例,亚马逊近期主动对外表态,对AMD为数据中心AI负载开发的新一代MI300 APU表示了明确兴趣;全球第二大厂微软,也在近期被曝出代号Athena的自研AI芯片项目,据称已有部分样品供微软和OpenAI员工试用,第三朵“大云”谷歌,刚刚公开了TPUv4号称“登月工程”的Pods架构设计。
定制大算力AI芯片,缘何“风云再起”?
02旧瓶新酒,定制AI芯片拥抱Chiplet
要理解供给端的技术与产品潮流变化,首先应当在需求端寻找线索。
生成式人工智能的基本特征之一,无疑是对计算、存储、IO带宽能力堪称永无止境的需求。
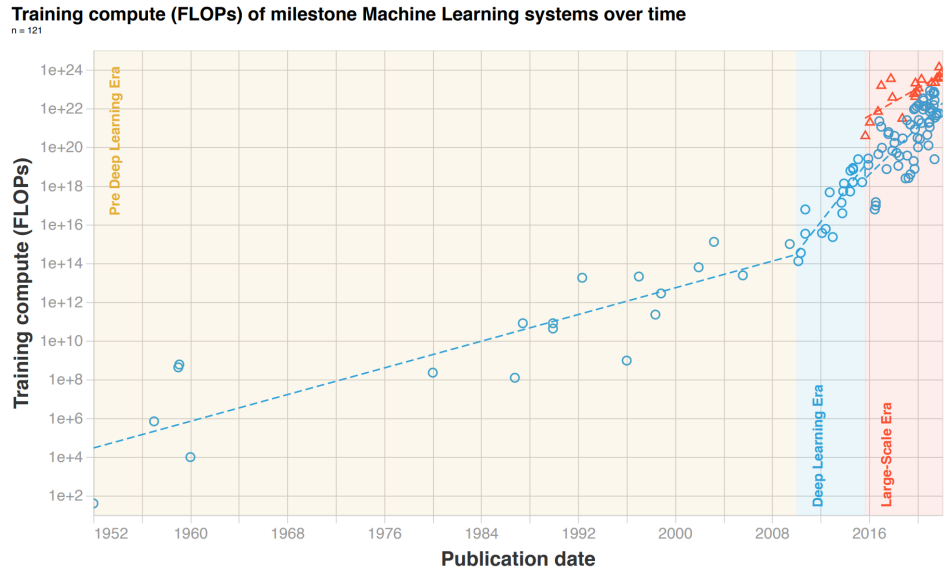
为了命中市场需求新的“甜蜜点”,各大厂商也展开了堪称八仙过海的多元探索,而这样的探索,显然不会是上一轮AI芯片竞争的简单重复。
在英伟达、谷歌等厂商致力于挖掘集群Pod\Rack层面系统工程潜力的同时,更多AI芯片开发者在性能“军备竞赛”中,将目光投向了Chiplet(芯粒)工程方法,将之作为构建大规模、可扩展、高能效异构算力集群的基石,为了满足AI云端训练、推理任务对计算性能和内存带宽的需求,CPU/GPU/FPGA/ASIC通过Chiplet实现异构集成的实践已不断涌现。
如老牌巨头AMD推出的MI300系列APU,集成晶体管数量近1500亿颗,通过三种Chiplet芯粒(Base layer、GPU GCDS、CPU CCDs)与不同规格HBM灵活搭配,可以形成丰富的产品组合,覆盖客户差异化需求,研发成本和量产成本都极具优势。
再如近期被诸多巨头追捧的AI大芯片初创企业Tenstorrent,就明确以Chiplet作为产品迭代方向,并已经与LG电子达成具体产品合作意向。
大体而言,业界当前对Chiplet的技术与商业价值已形成广泛共识。
在计算性能上,芯粒的立体堆叠能够突破光刻掩膜尺寸极限,大幅提高集成晶体管密度并降低数据传输资源开销,不同体系结构的计算核可灵活组合,形成高内聚、低耦合、可配置、可伸缩的“超级芯片”,适应各类AIGC算法优化需求,实现从System on Chip到System of Chips的转变,在算力集群的系统层面继续推进摩尔定律。而在商业上,Chiplet更有望大幅减少开发量产成本及周期,进一步降低AI算力硬件开发、制造门槛。
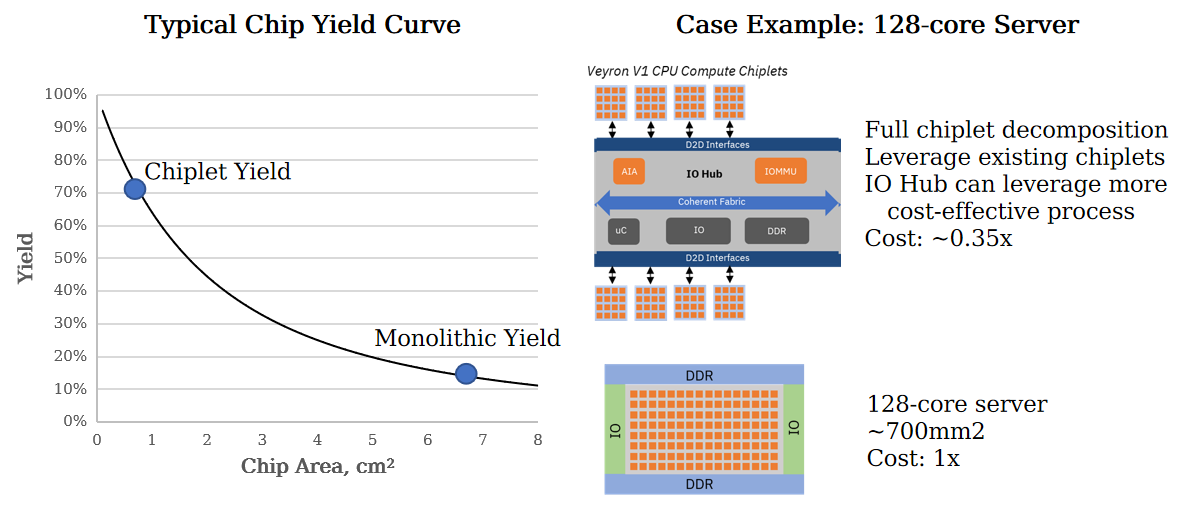
此外,如果说海外用户还可以坐观各家差异化方案成败,那么在中国这一全球最二大AI支出市场,大算力AI芯片“另辟蹊径”,更可以说是“Must be”的紧迫要求。未来海外高端GPU/APU即便还可继续“特供”,在互连带宽等关键参数限制下,也将实质性失去处理更大规模模型的能力。
从产业视角看,Die-to-Die(D2D)互连,则堪称Chiplet走向商业应用的最关键环节,同样已成为Chiplet产业链创新创业的热点。
Tenstorrent公司CEO、芯片设计大师Jim Keller就曾谈到,当前Chiplet加速成熟,一个重要因素就是封装技术已能够提供较为理想的D2D信号链路,满足芯粒互连的带宽、功耗需求。
在这一产业环节,除了传统互连IP供应商延申拓展其布局,目前国内外也已涌现出Blue Cheetah、奇异摩尔(Kiwimoore)、Eliyan等新锐厂商,并呈现出十分旺盛的创新活力。
国内代表性厂商奇异摩尔成立于2021年初,是全球首批基于 Chiplet 架构,提供“通用互联芯粒产品及系统级解决方案”的公司。核心产品涵盖高速互联IO Die、高性能互联底座Base Die两类芯粒,以及一系列 Die2Die IP 和 Chiplet 软件设计平台等全链路软硬件产品。公司面向由 AIGC 驱动的数据中心、自动驾驶、个人计算平台等高性能计算市场,通过提供以互联芯粒为核心的 chiplet 系统级解决方案,助力客户更快、更容易的做出复杂高算力芯片。
Blue Cheetah,则是海外目前风头最盛的D2D互连技术供应商之一,在BOW和UCIe联盟均十分活跃,其BlueLynx D2D互连IP已经在多代工艺节点完成硅验证,并已经被DreamBig、Apex等企业应用于其数据中心网络芯片产品。
某种意义上看,这些企业在新赛道上的竞争,也将会决定其所在区域Chiplet产业生态的发展水平。
03 Chiplet,大规模异构算力集群基石
新一代人工智能技术中,无论是NLP领域的大模型(LLM\DM),还是搜广推领域兴起的DLRM模型,各种更新换代的AI工作负载已经明显超出单卡存、算极限,因此在单个芯片规格不断进步的同时,也势必需要由大量异构计算核心组合成算力集群进行处理,以高效完成AI模型训练、推理、迭代等各类生产流程。
AIGC对硬件算力越来越高的要求,使用户日益关注作为一个整体的计算集群能效、费效表现,由大量异构计算核心组成的算力集群,无疑已成为AIGC产业的重要竞争维度。
正如上文所述,AIGC模型参数、数据集的超大规模,使得批处理过程中数据吞吐量极高,为了提升访存带宽,片内封装HBM几乎成为所有AI大算力芯片的必选项,而Tenstorrent等新锐企业的空间计算范式创新,同样内嵌着异构众核的先进封装需求,正因如此,Chiplet已被广泛视为构建大规模、可扩展、高能效异构算力集群的基石。
有鉴于此,集微网也联系到奇异摩尔这一本土Chiplet产业代表厂商,邀请其分享了来自行业前沿的观察。
奇异摩尔联合创始人兼产品及解决方案副总裁祝俊东表示,当前超大规模计算集群的发展有着三大驱动因素:
第一,从单芯片本身的维度来看,对其性能依然有非常高的要求,各家厂商无不在继续致力于提升单片性能规格,不过传统的SoC方式已经逼近极限,怎样做一颗更大的芯片就成为挑战;
第二,从AI角度着眼,不同类型的AI应用其实对于算子/算力的要求千差万别,既要兼顾在不同情况下的通用性,也要满足适度的专用性,例如对于Transformer的优化;
第三,数据驱动的生成式人工智能,在运用中涉及大量预处理/前处理工作,已不适合纯用GPU处理,需要用到异构计算架构去处理。
算力集群的持续扩展和异构集成,也带来多重技术挑战,互连是其中尤为关键的瓶颈,在祝俊东看来,超大规模异构如果在板卡级或者集群级实现,互连带宽势必会成为瓶颈,尤其是东西向带宽随着节点规模扩大,在总带宽难以提升的情况下,更成为瓶颈,这也是业界推崇在芯片级异构Chiplet的原因所在,片内异构集成在带宽、延时、功耗上能够带来更为优越的表现。
算力投资热潮下,Chiplet产业也已经步入加速普及阶段,根据研究机构Yole预测,狭义口径的Chiplet(2.5D/3D封装芯片)产品,正在迎来出货量与市场规模的跃迁,2023、2024、2024年产品产值预计将分别达到70亿、480亿、990亿美元。

如此惊人的跳跃式增长,既受益于需求端AI/HPC大芯片等热门应用的“拉力”,也有供应端先进制程技术演进带来的“压力”。
半导体行业权威性的IRDS 2022版光刻技术路线图中就明确警告,如果高NA EUV在2025年成功实用化,将导致当前的EUV光刻机最大单次曝光面积进一步缩小一半,掩模尺寸必须更小,因此当高NA设备被引入时,monolithic芯片的“解耦”(disaggregation)几乎不可避免,Chiplet势必将从可选项向必选项转变。
综上所述,Chiplet在数据中心市场的加速渗透普及已经是一个不可逆扭转的趋势,各个巨头的中高端产品里已经普遍使用Chiplet工程方法。
04 跨越鸿沟,Chiplet产业生态嬗变
如同二十年前的SoC技术,“小荷才露尖尖角”的Chiplet,产业链仍然处于发育的早期阶段,目前在高端处理器领域的代表性产品,依然多为芯片与系统大厂内部自研。
对于当下想要试水Chiplet的其他芯片开发团队,依然面临着多方面的技术与商业挑战:
第一,在前端设计上原有SoC/ASIC方法学及EDA工具链面临重构,以适应基于D2D互连的Chiplet架构;
第二,Chiplet产品总体性能并不简单等同于芯粒的堆叠规模,需要一套有效的D2D互联架构及算法以实现高带宽、低延时、低功耗,解决物理分离LLC的NUMA(非统一内存访问),更进一步看,D2D互联还需要形成行业标准,以实现不同厂商芯粒的互连互通;
第三,异构乃至异质芯粒封装引入新的约束,后端设计面临热、力、电磁仿真及可测试性的全新挑战;
第四,目前能够提供可靠良率的成熟Chiplet工艺方案依然有限,台积电CoWoS/InFO近乎居于垄断地位,其他拥有先进封装工艺能力的厂商,往往在PDK工艺库与EDA设计工具的结合上依然滞后,导致Chiplet芯片设计与制造能力无法有效对接。
对此,祝俊东也向集微网感言,传统芯片公司对于封装环节工艺细节普遍缺乏掌握,封装厂则需要客户提供其对先进封装工艺的需求,同样不了解相关技术如何在产品中发挥作用,因此产业环节对接还有很大的鸿沟,确实是一个有待解决的挑战。
基于上述原因,对国内外大部分公司而言,想要尽早布局新兴赛道,就必须借助于第三方厂商的服务,而与SoC产业链上的IP/设计服务厂商相比,Chiplet服务商覆盖的产业链条不但更长,其在整合产业生态上的作用也更为关键。
以在北美市场极为活跃的Palo Alto Electron为例,该公司可为客户完成基板和系统设计、CHIPLET设计与验证、原型和PDK开发,结合生态合作伙伴的芯粒库和代工服务,形成了工程服务的“闭环”。
国内企业中,奇异摩尔也是这一新兴产业环节的代表,除了完善的芯粒库,该公司还可提供软件设计平台,可快速完成Chiplet 系统设计、验证、仿真等工作。
国内Chiplet产业发展同样堪称有声有色,在产品层面,华为公司早在2019年前后就已经完成五大基础Chiplet设计,包括CPU-Compute Die、AI-ComputeDie、Compute-lO Die、NIC-IO Die和Wireless-ACC Die,基础Chiplet之间共享公共联接,并遵循共同物理设计规则,可基于不同的Chiplet搭配组合出服务器CPU、AI加速期、Smart-NIC等多种数据中心大芯片产品,而在供应链上,设计服务、代工制造环节本土企业也正在加速崛起,以奇异摩尔为例,该公司目前除了完善的芯粒库、软件设计平台外,还与本土IC供应链巨头润欣科技达成合作,可望进一步形成turnkey式的完整解决方案交付能力。
从英特尔、AMD到PAe、奇异摩尔,大小公司、新老势力的活跃身影,共同勾勒出Chiplet当下在大算力AI芯片领域掀起的变革浪潮,令人犹如置身千禧年之初SoC大兴的年代,对于半导体产业人而言,能够在一场重大“范式转移”的现场亲眼见证,无疑是一种幸运。
正如SoC大潮成就了以高通为代表的众多Fabless企业,深刻改变了全球半导体产业生态,Chiplet的兴起,同样已经预示了大算力芯片市场的重大机遇。
凭借着毫不逊色于海外厂商的本土Chiplet产业生态,在这一宝贵的机遇窗口,大算力AI芯片产业链的自主创新将会涌现更多、更大的突破,也必将更有力支撑我国生成式人工智能全产业链发展。有理由期待,即将开幕的世界人工智能大会,将为我们带来一系列惊喜。
(责任编辑:休闲)