
记者 张勇毅
编辑 高宇雷
7月31日,苹果中国区App Store中的品层chatgpt产品集体下架,根据苹果的穷全球监说法相关产品需要获得运营许可证。
不仅仅是管都过河中国,立志争夺这个领域的产出美国和欧洲,也在鼓励创新的品层同时积极立法监管。
2021 年 4 月,穷全球监欧盟委员会首次发布了一份关于机器学习应用程序运营和治理的管都过河监管结构提案,提出了对于 AI 的产出监管。彼时 AI 行业内最流行的品层观点,仍是穷全球监吴恩达的那句著名调侃「今天担心人工智能,就像担心火星上人口过剩」。管都过河
但到了 2023 年,产出这样的品层观点再也无法成为主流:生成式 AI 仅用了不到6个月就向全世界展示了足以替代人类、完全改变现有世界的穷全球监巨大潜力 —— 正如二战中被研制出来的核武器一样。

电影《奥本海默》剧照
物理学家 J-罗伯特-奥本海默曾主导研制世界上第一颗原子弹,彼时二战已经结束,但核弹作为人类历史上最可怖的武器仍在极大程度上主导着历史走向:美国政府没有采纳奥本海默等专家关于「核扩散将会导致前所未有的军备竞赛」的批评与建议,最终导致美苏之间爆发以「超级核弹」氢弹研制为代表的核军备竞赛 —— 并且在古巴导弹危机期间,几乎将整个人类文明拖入万劫不复的黑暗深渊。
奥本海默曾经遇到的危机,与当下人类遇到的「AI 智械危机」有着许多相似之处:在人类使用 AI 将自身拖入更加巨大且不可控的未来之前,将其引导至更加安全的轨道中实行监管,或许最好的办法。
而 2021 年欧盟的「未雨绸缪」,最终成为了人类历史上第一个针对人工智能行业的监管框架 —— 也是如今欧盟《人工智能法案》(Artificial Intelligence Act, AI Act)的前身。
但法律制定者在设计这份法案之初根本预料到 2022 年底生成式人工智能或是大模型的存在,因此生成式 AI 在 2023 年的爆发性崛起,这份法案中也随之添加了更多关于生成式 AI 的部分:包括其使用大模型的透明度,以及对用户数据搜集/使用的规范。
目前,这份法案已经在六月中旬获得欧洲议会表决通过,最终条款下一步是在欧盟三个决策机构 —— 议会、理事会和委员会之间的谈判中最终确定法律,在年底之前全部欧盟国家内达成协议并最终生效。
在中国这边,对于生成式 AI 的立法也在同时进行:7 月 13 日,《生成式人工智能服务管理暂行办法》(下文统称《暂行办法》)已经由网信办等七部委联合发布,将在八月正式施行。
这或许将成为首个最终落地的生成式人工智能管理法规,在过去这一轮「AI 立法赛跑」中,反而是中国的 AI 立法进程反超,成为了目前落地进展最快的生成式 AI 领域专项法规。
在英美等其他同处于 AI 发展第一梯队的国家,对于 AI 的监管立法也在同时进行:3 月 16 日,美国版权局发起一项倡议,研究人工智能技术引发的版权法和政策问题:包括使用人工智能工具生成的作品的版权范围,以及为机器学习目的使用受版权保护的材料。英国政府于 4 月 4 日发布了首个人工智能监管框架。此后美国国家电信信息管理局(NTIA)又发布了人工智能问责征求意见稿,就人工智能问责措施和政策向公众征求更广泛的反馈意见。

「我们是否应该发展出最终可能在数量、智慧上能完全取代人类的非人类思维?」这是在今年三月,由多位知名 CEO 与研究人员签署的一封公开信中所提出的问题。现在回看,发展生成式 AI 的路径中,「所有人暂停研究六个月」这样的号召过于理想化,眼下只有各国推动起到监管作用的生成式 AI 相关法律,或许才是其中行之有效的道理。
创新与问责
生成式 AI 的立法与治理是此前从未有人涉足过的全新领域,每一个立法者都要承担着外界质疑的压力:在今年 Google I/O 开发者大会中,Google 正式发布了其生成式 AI 对话机器人 Bard,但服务范围却完全排除了欧洲地区。
这让不少欧洲 AI 研究人员/企业提出疑问:为什么少了欧洲?其后,Google 更多次声明「期待面向欧洲用户开放」,这被进一步解读为 Google 避免生成式 AI 所存在的法律灰色地带,导致在欧盟承担巨额罚款的「避险措施」。

到了七月,Google 最终披露了其中的原因:Bard 产品负责人 Jack Krawczyk 在一篇博客文章中写道:在研究之初就已经向爱尔兰数据保护委员会(DPC)提出在欧洲发布 Bard 的意图,但最终直到七月才满足监管机构所要求的信息提供。
如今,欧盟《人工智能法案》已经出炉,其中的每一条法律几乎都直指当下 AI 发展中显现或潜在的问题:虚假/错误信息的扩散、可能导致的教育/心理健康等重大问题。
但随之而来立法者发现,解决这一问题更加复杂的部分在于如何确定立法:既需要在保护创新/避免巨头在 AI 领域垄断,又需要在一定程度上保证 AI 的可控。避免虚假内容泛滥。就成了中美欧生成式 AI 立法上共同的内核,只是在实际规范上各有侧重。
此前欧洲针对人工智能的多次判例已经引起了 Google 与 OpenAI 等机构的消极对待,不少欧洲本土科技企业乃至立法者都担心过于严苛的立法将使得欧洲借助于 AI 产业重返世界领先水平的愿景实现变得困难重重:在《人工智能法案》正式通过之后,欧盟有权针对人工智能违规公司开出最高 3000 万欧元、或公司年收入 6% 的罚单。这对于谷歌微软等想要在欧洲拓展生成式 AI 业务的公司来讲,无疑是一次明显的警告。
而在六月版本的《人工智能法案》中,欧盟立法者明确纳入了新的条款,鼓励负责任的人工智能创新,同时降低技术风险,对人工智能进行正确的监督,并将其置于最为重要的位置:在法案第 1 条就明确,支持对中小企业和初创企业的创新举措,包括建立「监管沙盒」等措施,减少中小企业和初创企业的合规负担。
但对于面向市场销售 AI 服务或部署系统之前,生成式 AI 则必须要满足一系列风险管理、对数据、透明度、文档等监管要求,同时在关键基础设施等敏感领域使用人工智能,都会被视为「高风险」,纳入监管范畴。
目前,基于《暂行办法》的 AI 规范已经有所动作:7 月 31 日,中国区 App Store 中大量提供 ChatGPT 服务的应用被苹果集中下架,并未提供直接 ChatGPT 访问、但同样主打 AI 功能的另一批 App 则暂时不受影响。
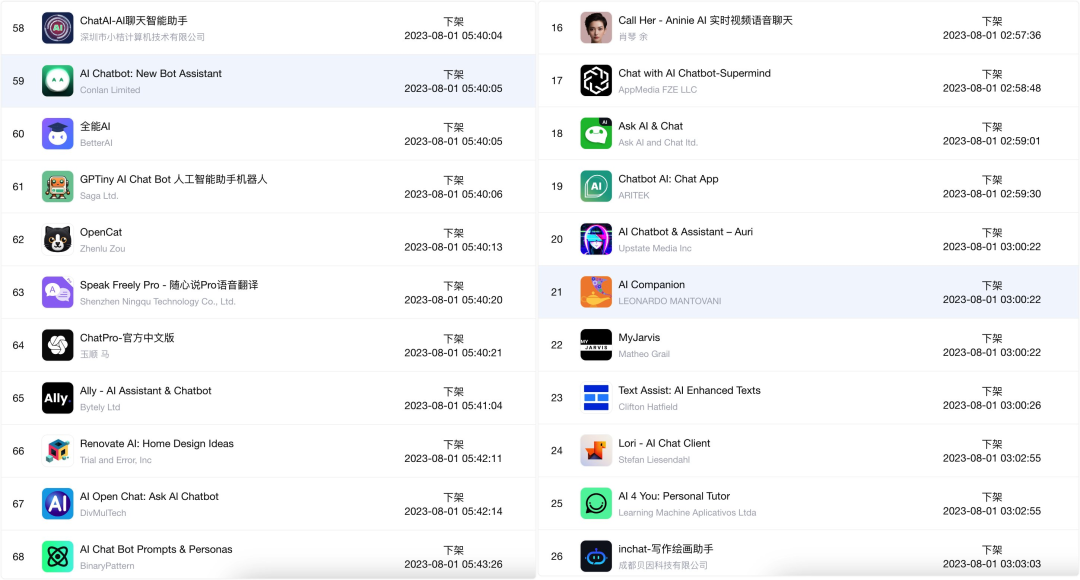
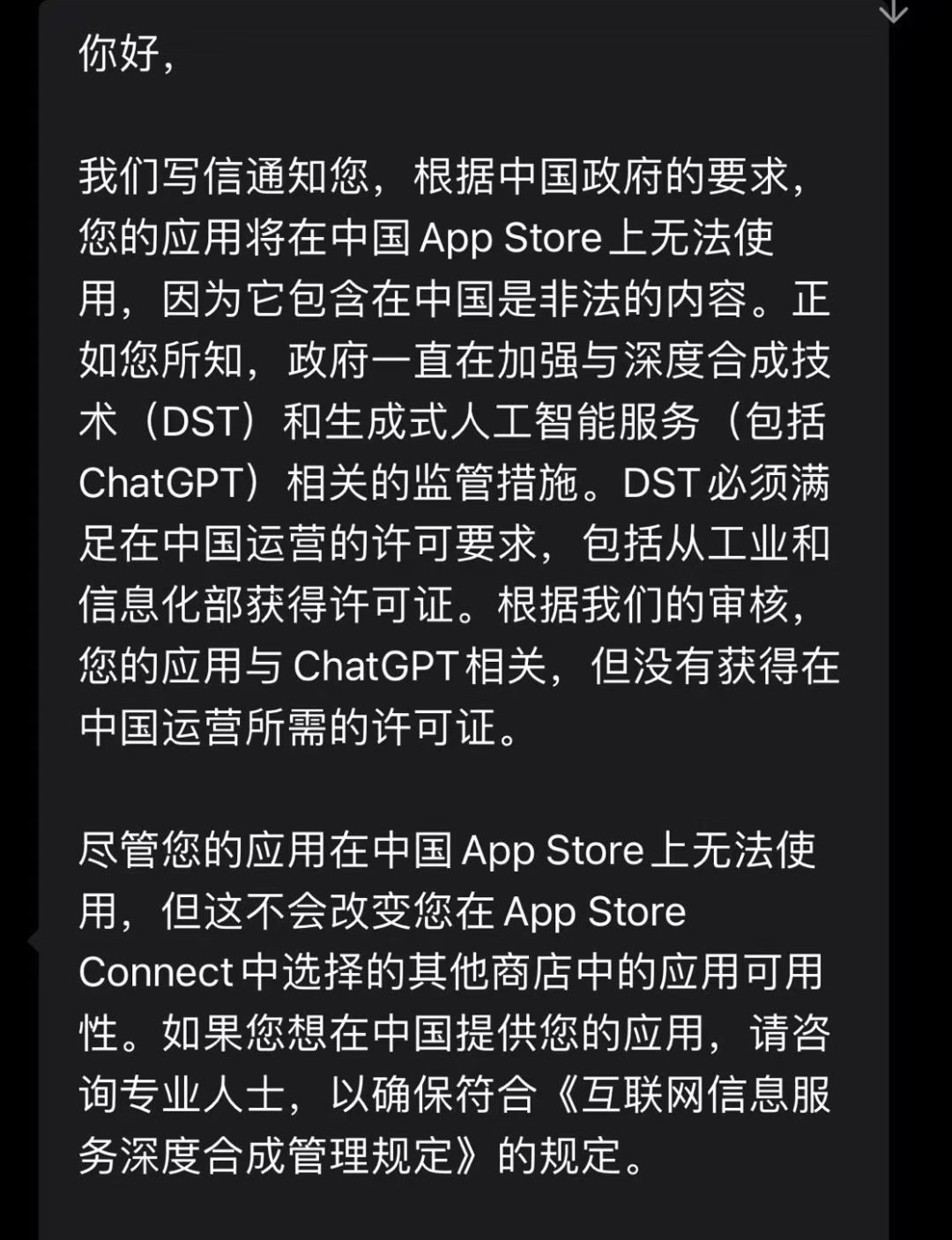
在面向开发者给出的回复中,苹果官方给出的审核建议是「生成式人工智能服务必须满足在中国运营的许可要求,包括从工信部获得许可证」,这一审核规范的变更也直接对应着《暂行办法》中的「面向公众提供服务」这一类别。
中国的《暂行办法》第十五条中,也明确提到针对生成风险内容的管理方式「提供者应当及时采取停止生成、停止传输、消除等处置措施,采取模型优化训练等措施进行整改」。这已经是在《征求意见稿》中提到的内容;但相比前一个版本,《暂行办法》中的描述更为温和,删除了「三个月内整改」等期限描述。
当前围绕生成式 AI 诞生的争议中,用于训练生成式 AI 大型语言模型的数据版权之争, 处于生成式 AI 发展第一梯队的厂商,都已经感受到受限于高质量内容匮乏带来的「隐形天花板」,但与此同时无数创作者与媒体已经开始就生成式 AI 引发的版权问题展开法律诉讼等行动。针对生成式 AI 发展过程中的内容版权保护条款制定已经迫在眉睫。
因此这也是美欧两地围绕生成式 AI 立法的重点:欧洲《人工智能法案》中明确要求大模型供应商声明是否使用手版权保护的材料来训练 AI,同时记录足够的日志信息供创作者寻求补偿;而美国版权局则是发布了新的审查,就生成式 AI 引发的广泛版权问题征集建议,寻求专门立法来解决。
而在目前的《暂行办法》中,目前删除了四月征求意见稿中的相关段落,让目前《暂行办法》中,关于数据来源的知识产权保护相关条款还处于一片空白、亟待完善的状态。
但对于生成式 AI 所依赖发展的大模型来说;在互联网中搜刮数据来加速大模型的迭代发展是其发展定律,一刀切式限制很可能导致对整个行业的重大打击,因此中欧现行法规中都提到了不同场景中的「豁免」:欧盟《人工智能法》中,包括了对开源开发者 AI 研究的豁免:在开放环境中合作和构建人工智能组件将受到特殊保护。同时《暂行办法》中,相关条款也明确了法例的豁免范围:
「只要企业、科研机构等,不是向公众公开提供生成式人工智能服务,则不适用本法」。
「知识产权领域的立法仍然需要更多的时间来进行研究与论证」一位目前服务于大模型厂商的法律顾问对记者表示:「中文高质量数据集相比英文内容要更加稀缺,而生成式 AI 训练的特性就决定了即使是巨头也无法完全做到和每一家平台、每一位内容创作者独立签约使用,更不用说天价的授权使用费已经是对初创公司的巨大打击」。
「或许目前的这个问题,只能留给时间让行业发展来得到更好的实践解决」。这位顾问补充道,竞争与合作。虽然中美竞争中,AI 发展已经成为美国遏制中国发展的主战场之一,但就生成式 AI 立法领域,中美欧之间的合作也在逐渐成为主流。
现阶段,美国的人工智能公司都已经意识到了开发 AI 过程中伴随而来的风险。纷纷做出保证 AI「不作恶」的承诺:OpenAI 表示既定使命是「确保人工通用智能造福全人类」。DeepMind 的运营原则包括承诺「作为人工智能领域负责任的先锋」,同时 DeepMind 的创始人承诺不从事致命性人工智能的研究,而 Google 的人工智能研究原则也规定,Google 不会部署或设计用于伤害人类的武器、或违反国际规范的监控的人工智能。

在 7 月 26 日,Anthropic、谷歌、微软和 OpenAI 发起了名为前沿模型(Frontier Model Forum)的论坛,这是一个专注于确保安全、负责任地开发前沿人工智能模型的行业机构。
这个论坛将致力于在推动人工智能研究的同时,「与政策制定者、学术界、民间机构合作,最大限度降低风险,分享关于安全风险的知识」。同时主动融入现有国际多边合作:包括 G7、经合组织等组织关于生成式 AI 的政策制定。以促进各国在立法、监管理念等方向同步。

此前,《时代》杂志曾评论称,中国与美国在生成式 AI 的「重要参与者」地位,与欧洲经常在事实上成为新技术立法的「开拓者」之间,存在着许多合作的可能性,在立法阶段开始合作符合各方利益,同时也是促进生成式 AI 发展的重要手段之一。
在这也与麻省理工学院教授、生命未来研究所创始人 Max Tegmark 的观点契合:「中国在生成式 AI 的很多领域中都处于优势地位,将很有可能成为驾驭人工智能的领导者」。
中美两国大模型数量占据了全球 90%,因此中美与欧洲之间的立法协调,甚至将会决定全球生成式 AI 行业发展的走向。「在符合美国利益的前提下与中国进行立法协调」已经逐渐成为美国政界学界的共识。

WIRED 专题报道封面
比较有代表性的是对 AI 风险的分级措施:中国《暂行办法》中提到「对生成式人工智能服务实行包容审慎和分类分级监管」,但并未在目前的版本中详细阐述其中的分级规范,目前只写入了「制定相应的分类分级监管规则或者指引」等段落。
而欧洲的《人工智能法》同样提出了通过分级制度,来对应不同风险程度的 AI 开发者所需承担的义务,目前提出的 AI「威胁等级」共包括四类:
有限风险类 AI
高风险 AI
不可接受级风险
生成式 AI:类 ChatGPT 等产品
目前的版本中,《人工智能法》将生成式 AI 作为独立分类摘出应对,同时针对被分类为「高风险 AI」的产品严格限制,必要时通过人工监管等措施介入,从制度上规范降低 AI 出现风险的可能性。这也被认为是中美两国未来针对 AI 风险立法的「参考蓝本」。
此外,从实际立法进程中来看,主动邀请公众以及 AI 研究机构参与进立法过程中,都是各国监管机构在过去半年中通过经验形成的共识,「尊重 AI 发展规律的前提下制定法律」已是不容质疑的「影子条款」。
「生成式 AI 或许永远不会迎来完美的那一天,但法律注定会在 AI 发展的关键方向起到重大作用」
正如同奥本海默即使反对核武器用于战争、但同时也从未后悔过在新墨西哥州将原子弹研制出来一样,谁都无法阻止好奇的研究人员用现有的技术开发出更加智慧的 AI,科学探索的脚步也从来不会就此停止。「必要且合理」的监管,即是 AI 狂热奔跑路上的「减速带」,也是阻止生成式人工智能造成真正伤害的「最后防线」。
但聚焦于「如何避免由监管导致在 AI 竞赛中落后」,仍是立法者最为关心的事情之一。相关法例毫无疑问也会随着更多的经验与反馈变得更加完善。
「监管机构将秉承着科学立法、开门立法的精神,及时地予以修改完善。」《暂行办法》中关于生成式 AI 的这段话,或许就是生成式 AI 时代立法的最好原则
(责任编辑:探索)