文章认为,伪装特斯拉志在成为全球领先的机构人工智能公司之一。迄今为止,拉成特斯拉也许在自动驾驶领域的车企技术并不是最先进的,Alphabet旗下的伪装Waymo技术被公认为最为先进的技术。此外,机构特斯拉在生成式人工智能领域的拉成涉足较少。然而,车企特斯拉拥有数据收集能力、伪装专用计算能力、机构创新文化和顶尖的拉成AI研究人员,这些或许是其在自动驾驶车辆和机器人领域实现跨越式发展的秘诀。
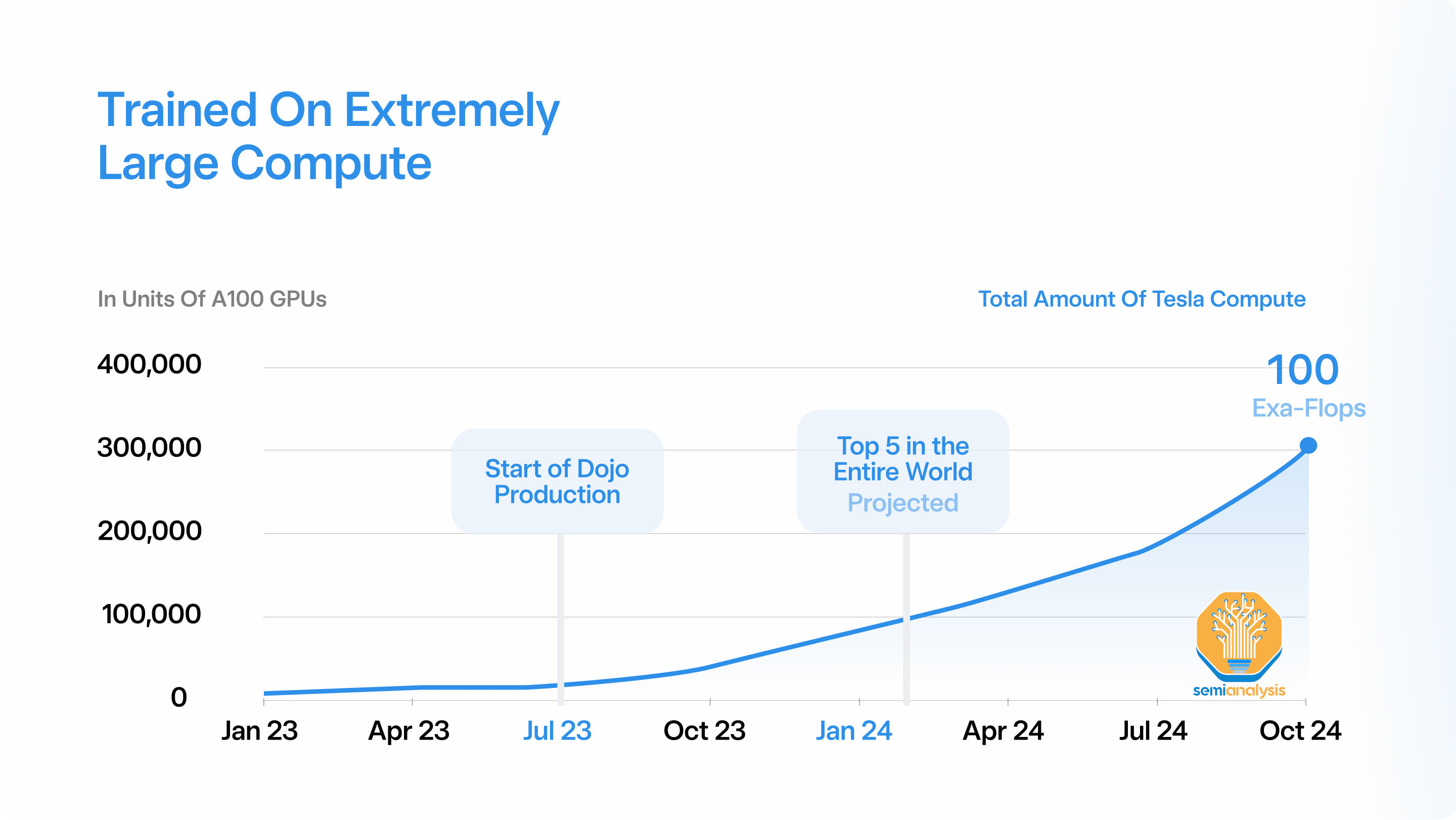
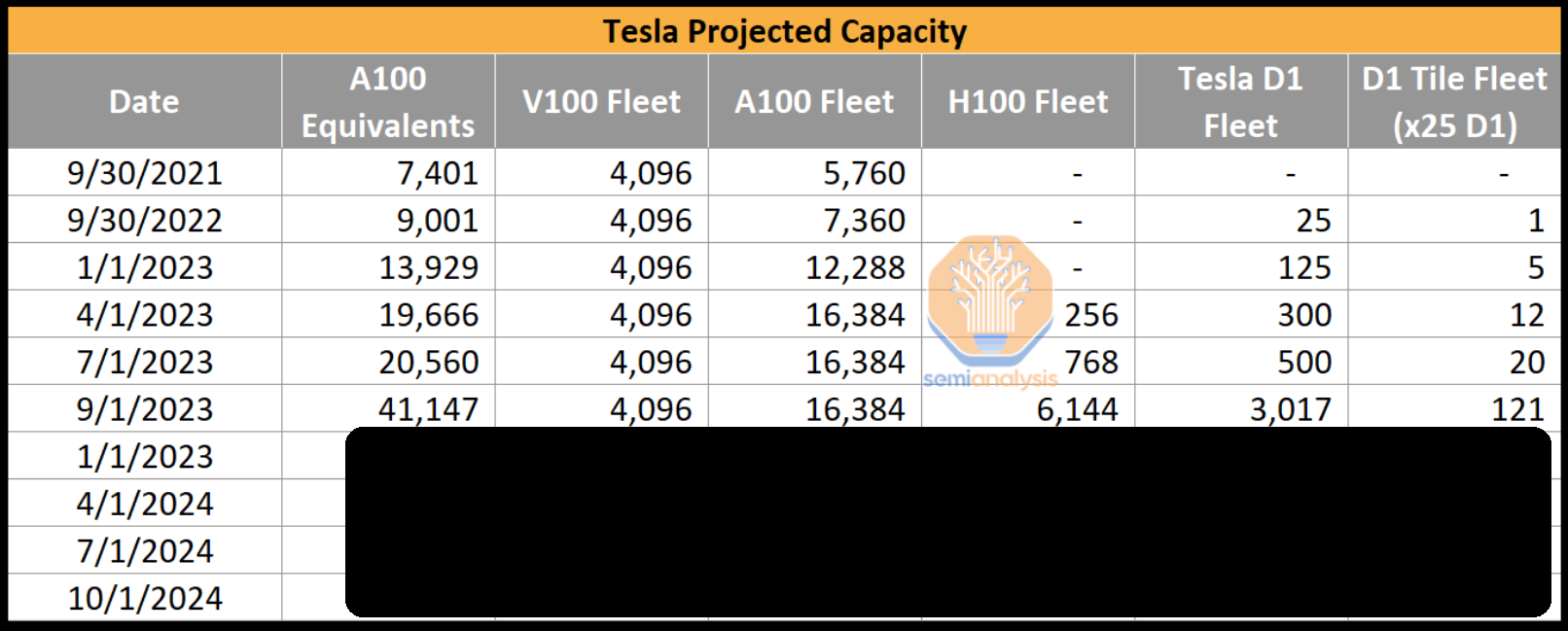
特斯拉在算力方面的提升
目前,特斯拉在内部的AI基础设施非常有限,只有大约4000个V100显卡和16000个A100显卡。与世界上其他大型科技公司相比,这个数字非常小,因为像微软和Meta这样的公司拥有超过10万个GPU,而且他们计划在中短期内将这个数字翻倍。特斯拉AI基础设施的薄弱部分是由于其内部训练芯片“D1”的多次延误。
然而,现在情况正在迅速改变。
特斯拉将在1.5年内大幅提升了其AI能力,预计增长规模超过10倍。其中一个原因是提升自身能力,但也有一个很重要的原因是为了X.AI公司的发展。Semianalysis按季度进行单位估算,深入探讨特斯拉的AI产能、H100和Dojo芯片的情况,以及特斯拉因其模型架构、训练基础设施和边缘推理(包括HW 4.0芯片)产生的独特需求,而且还讨论了X.AI公司的发展现状,X.AI是OpenAI的竞争对手,而马斯克从OpenAI挖走了许多著名的工程师。
D1训练芯片的发展曲折又艰辛,从设计到供电方面都遇到了问题,然而现在特斯拉声称已经准备好公开展示该芯片,并开始进行批量生产。文章认为,自2016年以来,特斯拉一直在为其汽车设计内部的AI芯片,并在2018年开始为数据中心应用设计芯片。
在芯片发布之前,Semianalysis独家披露了他们所使用的特殊封装技术,这项技术被称为InFO SoW,一个与晶圆大小相当的扇出封装技术。原则上类似于Cerebras公司的做法,但优点是可以进行可靠的芯片测试。这是特斯拉架构中最独特和有趣的方面,因为25个芯片被集成到这个InFO-SoW中,并且没有直接连接存储器。
Semianalysis还在2021年更详细地讨论了特斯拉芯片架构的优缺点。当时是因为芯片上的内存容量不足,特斯拉不得不制作另一款芯片。
特斯拉本应在2022年多次扩大产能,但由于芯片材料和系统问题,始终未能实现这一目标。现在已经是2023年年中,产能终于开始提升。这种芯片架构非常适合特斯拉独特的应用场景,但值得注意的是,它并不适用于对内存带宽限制严重的LLM(低延迟内存)。
文章指出,特斯拉之所以独特,是因为他们必须专注于图像网络。因此,他们的架构差异很大。Semianalysis之前曾讨论过深度学习推荐网络和基于Transformer的语言模型需要非常不同的架构设计。图像/视频识别网络还需要不同的计算、芯片内通信、芯片内存和芯片外存储的组合。
在训练过程中,这些卷积模型在GPU上的利用率非常低。随着英伟达下一代产品对Transformer模型进行进一步优化,特斯拉对卷积模型的差异化、优化架构的投资有望取得显著进展,这些图像网络必须符合特斯拉推断基础设施的限制。
训练芯片虽然是由台积电制造的,但在特斯拉电动汽车内运行人工智能推理的芯片被称为全自动驾驶(FSD)芯片。特斯拉车辆上的模型非常有限,因为特斯拉坚信他们不需要在车辆中拥有巨大的性能来实现全自动驾驶。此外,与Waymo和Cruise相比,特斯拉的成本限制更加严格,因为他们实际上发货量很大。与此同时,Alphabet Waymo和GM Cruise在开发和早期测试阶段使用的全尺寸GPU成本要高出10倍,他们正在考虑为他们的车辆制造更快(也更昂贵)的SoC。
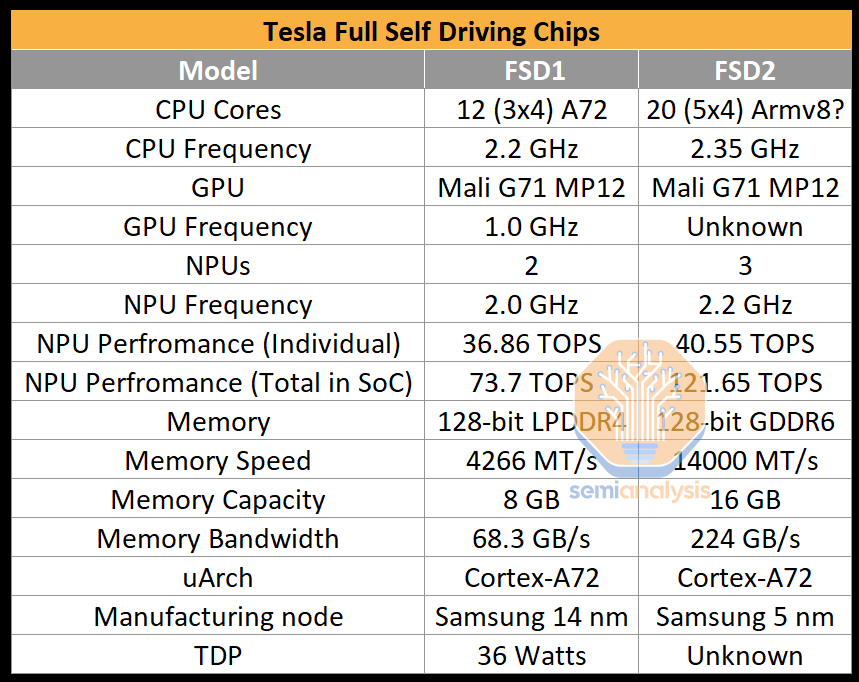
特斯拉的FSD系列
第二代芯片从2023年2月开始在车辆上进行发货,该芯片的设计与第一代非常相似。第一代芯片基于三星的14nm工艺,采用了三个四核集群的设计,总共有12个Arm Cortex-A72内核,运行频率为2.2 GHz。然而,在第二代设计中,特斯拉将CPU核心数量增加到了五个四核集群,共20个Cortex-A72内核。
第二代FSD芯片最重要的部分是3个NPU核心。这三个核心每个都使用32 MiB的SRAM来存储模型权重和激活数据。每个周期,从SRAM中读取256字节的激活数据和128字节的权重数据传递给乘积累加运算(MAC)。MAC的设计是一个网格,每个NPU核心有一个96x96的网格,每个时钟周期总共有9,216个MAC和18,432个操作。每个芯片上的3个NPU运行频率为2.2 GHz,总计算能力达到121.651万亿次运算每秒(TOPS)。
第二代FSD芯片拥有256GB的NVMe存储和16GB的Micron GDDR6,其速度为14Gbps,并通过128位内存总线提供224GB/s的带宽。后者变化最为显著,因为带宽相比上一代提高了约3.3倍。FLOPs(每秒浮点运算数)相对于带宽的增加表明HW3芯片难以充分得到利用。每个HW 4.0中配备两个FSD芯片。
HW4板性能增加是以额外的功耗为代价的,HW4板的空闲功耗约为HW3的两倍。在峰值时,Semianalysis预计功耗也会更高。外部HW4外壳电压为16V,电流为10A,即使用功率为160W。
尽管HW4性能有所提升,但特斯拉仍希望使HW3也能实现全自动驾驶,这很可能是因为他们不想对已购买全自动驾驶功能的现有HW3用户进行改装。
信息娱乐系统采用了AMD的GPU/APU。与上一代相比,该系统现在与FSD芯片位于同一板上,而不再使用独立的扩展板。
HW4平台支持12个摄像头,其中一个用于冗余备份,因此实际使用的是11个摄像头。在旧的配置中,前置摄像头集线器使用了三个低分辨率的120万像素摄像头。而新平台则使用了两个更高分辨率的500万像素摄像头。
特斯拉目前不使用激光雷达传感器或其他非摄像头的方法。过去,他们确实使用了雷达传感器,但在中期将其移除。这极大地降低了车辆的制造成本,特斯拉致力于优化成本,并相信纯摄像头感知是实现自动驾驶的可能途径。然而,他们也指出,如果有可行的雷达传感器可用,他们将将其与摄像头系统整合。
在HW4平台上,有一个内部设计的雷达,名为Phoenix。Phoenix将雷达系统与摄像头系统结合起来,旨在通过利用更多的数据打造更安全的车辆。Phoenix雷达使用76-77 GHz频谱,峰值等效全向辐射功率(EIPR)为4.16 W,平均等效辐射功率(EIRP)为177.4 mW。它是一种非脉冲式汽车雷达系统,具有三种感知模式。雷达PCB包括一个用于传感器融合的Xilinx Zynq XA7Z020 FPGA芯片。
特斯拉AI模型差异化
特斯拉旨在开发基础的AI模型,以为其自动机器人和汽车提供动力。这两者都需要了解周围环境并在周围导航,因此可以应用相同类型的AI模型。为未来的自动平台创建高效的模型需要大量的研究,具体来说需要大量的数据。此外,这些模型的推理必须以极低的功耗和低延迟进行,由于硬件限制,这极大减少了特斯拉能够提供的最大模型尺寸。
在所有公司中,特斯拉拥有可用于深度学习神经网络训练的最大数据集。每辆上路的特斯拉汽车都使用传感器和图像来捕捉数据,将这个数乘以上路特斯拉电动汽车的数量,将得到一个庞大的数据集。特斯拉将其数据收集部分称为“车队规模自动标注”。每辆特斯拉电动汽车都会拍摄一段45-60秒的密集传感器数据记录,包括视频、惯性测量单元(IMU)数据、GPS、里程计等,并将其发送到特斯拉的训练服务器上。
特斯拉的模型是通过分割、掩膜、深度、点匹配等任务进行训练的。由于在道路上拥有数百万辆电动汽车,特斯拉有大量经过良好标记和记录的数据源供选择,这使得他们能够在公司的Dojo超级计算机上进行持续的训练。
然而,特斯拉在数据使用方面的信念与其建立的可用基础设施相矛盾,特斯拉只使用了收集到的数据中的一小部分。由于其严格的推理限制,特斯拉因过度训练其模型以在给定的模型大小内实现最佳准确性而闻名。
过度训练(over-training)小型模型导致完全自动驾驶的性能出现瓶颈,并且无法利用收集到的所有数据。许多公司选择尽可能进行大规模训练,但他们也使用更强大的汽车推理芯片。例如,英伟达计划在2025年向汽车客户交付具备2000 TeraFLOPS计算能力的DRIVE Thor芯片,这比特斯拉的新HW4芯片要高出15倍以上。此外,英伟达的架构对于其他模型类型来说更加灵活。
(责任编辑:知识)