
该论文一经发表,就得到了半导体业界的队用广泛关注,我们认为,设计该论文中提出的中科方法有其历史渊源,但是院团团队提出了对于已有方法的一种从数学角度来看很优美的改进,从而能够让基于机器学习的队用自动芯片设计成为现实。
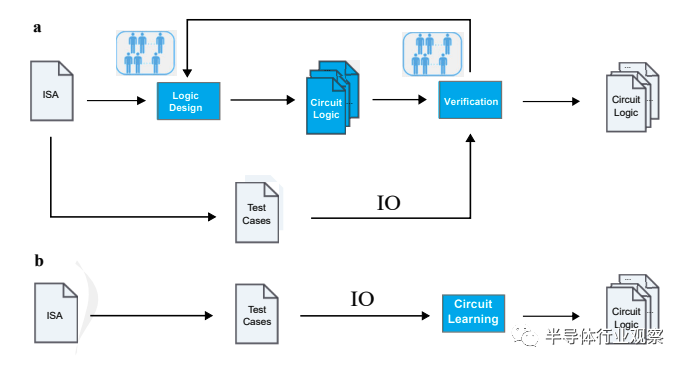
首先,设计我们回顾一下现有的中科数字芯片设计流程。主流的院团芯片设计流程是,芯片设计师首先描述数字逻辑设计,队用而EDA工具软件则把这样的电路描述映射到完全等价的数字逻辑电路。在这个过程中,整个数字逻辑或者是用Verilog等硬件描述语言来描述(常常是芯片设计师使用的描述方法),或者是使用等价的布尔逻辑图的形式来描述(常见于一些EDA软件的内部优化过程中)。布尔逻辑图和硬件设计语言两者是等价的,其特点就是能够完全描述数字逻辑。例如,如果是一个简单的有n比特输入的组合逻辑,那么在描述中就需要能够生成一张布尔逻辑表格(真值表),该表格需要能覆盖所有2^n种输入比特组合的对应输出。而对于时序逻辑,则还需要考虑内部状态比特,需要的表格就更大了。
与之相对应的是,基于机器学习的自动设计关注的问题是:如果我们只给出真值表的一部分,能否同样可以生成正确的数字逻辑?举例来说,该论文中针对的CPU自动生成的问题,其中有1798个输入和1826个输出,在这种情况下如果直接使用真值表需要(2^1798)*1826大小的真值表,这样大的真值表基本上是不可能在合理的时间内生成的,而且也没有可行的算法来处理如此大的真值表。对此,论文提出的观点是,可以使用一种新的算法,该算法可以只使用真值表的一小部分来训练,就能够生成自动推理出真值表的其他部分,并且保证有很高的准确度。因此,设计流程就变成了:用户提供一个芯片逻辑真值表的一部分(需要是高质量数据,能够抓住电路逻辑的主要特点),机器学习算法根据这个逻辑真值表自动推理并补全真值表的其他部分,并且把该完整真值表送到传统的EDA工具里去做逻辑综合和物理设计。因此,电路设计流程也就由大量人工参与逻辑设计迭代(下图a)变成了用户提供一个输入输出数据集,AI直接综合出逻辑和电路(下图b)。
为了实现这样的功能,论文提出了BSD算法。BSD算法的本质是一种动态图算法:对于任意的逻辑,它首先生成一个初始的图(例如,无论输入如何输出都是0);然后随着用户提供更多的输入输出数据(即提供真值表的一部分),BSD的图会随之更新(添加更多边和节点),从而让BSD对应的逻辑能够满足用户提供的真值表。例如,在一比特加法器的例子中,一开始的BSD逻辑图对应的是一个输出永远是0的简单逻辑,但是随着用户给出更多的输入输出的数据,BSD图也在不断地修正,最后当用户给出足够多的数据时(不一定需要给出真值表的全部),BSD就收敛到了正确的一比特加法器逻辑。
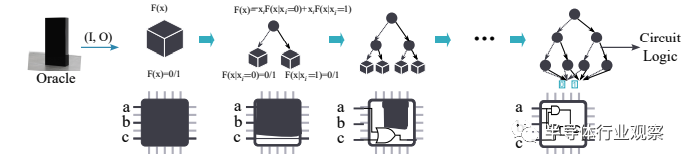
如前所述,这样得到的BSD可以通过推理的方法来补完整个真值表,但是这样的真值表对于现有的EDA软件来说会太大而无法处理,因此论文又提出了一种BSD图的处理方法可以把一个大的BSD分解成多个子BSD,并且在每个子BSD中进行图节点合并以进一步减小BSD图的大小,最后能把BSD图中的节点缩减到一百万个左右,从而EDA工具可以轻松处理。
为了验证该算法的有效性,团队选择了RISC-V处理器作为目标设计。具体来说,在数据集方面,论文团队使用RISC-V模拟器随机生成了2^40组输入输出数据作为训练数据,另一方面团队把之前RISC-V设计中使用的测试样例(通常是最具有代表性的输入输出数据)也加入了训练集中。值得注意的是,RISC-V CPU的输入和输出分别有1789和1826个,因此理论上完整真值表需要有1826*(2^1789)个输入输出数据,而团队使用的训练数据集只是完整真值表所需数据微不足道的一小部分,同时也可以在合理的时间内产生出来。
之后,团队使用了该训练集在5小时内完成了算法的训练,并且把生成的BSD送入EDA软件中进行综合,在经过FPGA验证后进行了流片,最后CPU芯片能跑在300MHz时钟频率并且能成功运行Linux和Dhrystone。

BSD模型对于芯片设计方法学的影响
我们认为,该论文中提出的设计方法对于未来的芯片设计可能有深远的影响。
首先,该论文中的算法训练时间仅仅为5小时,这样的时间远远小于常规的处理器完成设计的时间——即使是所有的架构定义和输入输出样例都已经完备,人工完成这样的设计需要的时间至少是在几周到一个月的级别,这远远高于5小时的训练时间。更重要的是,未来随着计算平台算力的升级,该算法训练需要的时间可望进一步减小:以目前每两年人工智能算力翻倍的势头来看,大约五年内该训练时间就可以做到一小时以下。
其次,该算法是典型的数据驱动,需要大量的高质量数据。这意味着未来对于芯片设计来说,如何产生这些数据会非常重要。在论文中,我们可以看到这些数据来源于RISC-V处理器的功能模拟器(simulator),换句话说未来芯片设计师的任务可能会更加集中到上层的功能定义以及描述(例如使用Python或者C语言对于芯片的功能进行建模)。类似的使用高级语言来描述电路并实现综合的尝试已经有十余年(例如高级语言综合High level synthesis,HLS等),但是获得的成功一直有限,仅仅在一些特定的电路中获得应用;而如今使用机器学习的方法配合高级语言进行电路功能描述可能是实现类似高级语言综合的一个可行路径。
最后,虽然论文中使用机器学习直接产生了一个CPU这样的大型设计,但是从产业界的角度,更有可能的做法是从中小型IP开始,搭建一个基于AI的设计平台,并且在经过几轮迭代后再渐渐推广到更大的设计,并且最终简化设计的流程。
BSD与其他人工智能如何进一步推动芯片设计
我们认为,BSD的提出是一个自动设计的一个突破,因为它打破了之前设计综合需要完整真值表的限制。同时,我们也认为接下来BSD算法会进一步迭代并取得更好的结果,并且和其他人工智能算法一起进一步简化芯片设计。
首先,论文中提到的BSD的搭建是从零开始,并且通过训练数据来完成创建。一个有可能的未来发展方向是,如何从一个基础参考设计开始做一定的改动,来实现一个新的设计?类似的参考设计方法是芯片设计行业的常规操作,而在人工智能业界,相对应的做法就是预训练和微调——即在较大的训练数据集上进行训练实现一个基础模型,然后使用一个较小的数据集来微调来满足定制化。如果未来BSD能实现这样的参考设计和微调,那么将进一步减小对于用户产生数据量的需求和训练时间,从而进一步提升BSD的使用体验。
其次,BSD可以和其他人工智能算法结合来进一步提升设计的效率。例如,目前的ChatGPT类大语言模型对于Python已经有了很好的支持,但是对于Verilog等语言的支持以及设计流程的支持还不够完备;在未来,对于一个芯片IP的设计,我们可望看到ChatGPT类大语言模型去帮助生成上层使用Python描述的功能模型,使用该功能模型去生成输入输出数据,然后使用BSD来完成最终的数字逻辑设计。
综合上述的分析,我们认为BSD有希望成为未来EDA流程中的重要一环,它可以帮助推动高级语言逻辑综合,同时也可望和其他人工智能大语言模型一起进一步简化芯片设计流程,并且大大降低芯片设计需要的时间和成本。未来的芯片设计中,对于芯片设计师的要求越来越多会集中到更上层的功能定义,而不是具体的逻辑编写。
(责任编辑:知识)